All courses
Agentic AI
Agentic AI
Artificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
IIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, SwitzerlandGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsMBA
Masters

Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Executive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
Offline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)Paris School of Business
Master of Science in Business Management and Technology
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
- uGSOT - B.Tech
More



14. Radix Sort
20. AVL Tree
21. Red-Black Tree
23. Expression Tree
24. Adjacency Matrix
36. Greedy Algorithm
42. Tower of Hanoi
43. Stack vs Heap
47. Fibonacci Heap
49. Sparse Matrix
50. Splay Tree
Doubly Linked List Data Structures: A Complete Guide
I've spent countless hours exploring various techniques to efficiently organize information. One structure that consistently stands out is the doubly linked list data structure. As a programmer, I find myself reaching for doubly linked lists in a surprising number of scenarios. Today, I'm here to share my experience and equip you with a comprehensive understanding of this powerful data structure.
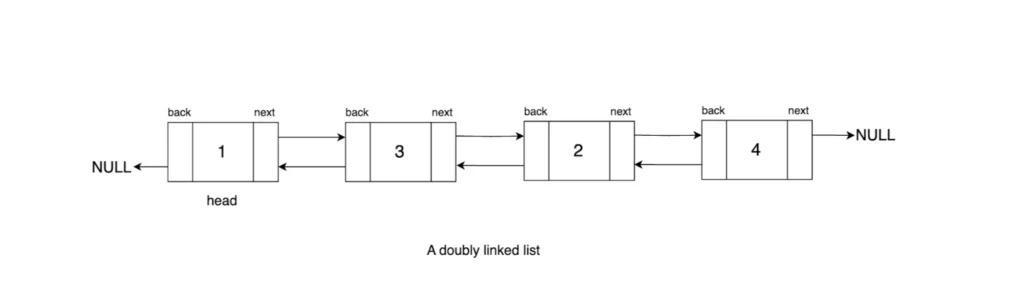
A doubly linked list's nodes, or members, are linear data structures with three fields each:
- Data: The information stored in the node (e.g., integers, characters).
- Next pointer: A reference to the next node in the list.
- Previous pointer: A reference to the previous node in the list.
This two-way navigation allows for efficient insertion. It also helps to delete, and traverse in both forward and backward directions.
Doubly linked list example (C++)
C++
struct Node {
int data;
Node* prev;
Node* next;
};
This code defines a Node structure with an integer data field and pointers to the prev and next nodes.
Doubly Linked List Data Structure Operations Supported
Doubly linked lists support various operations:
- Insertion: It adds new nodes at specific positions.
- Deletion: It removes existing nodes from the list.
- Traversal: It visits each node in the list (forward or backward).
Let's explore some common operations with doubly linked list examples.
Insertion at the Beginning
The provided code defines a function insertAtBeginning. It inserts a new node at the beginning of a doubly linked list data structure. It also acts as a main function that demonstrates its usage.
C++
void insertAtBeginning(Node** head_ref, int new_data) {
// Allocate memory for a new node
Node* new_node = new Node;
new_node->data = new_data;
new_node->prev = NULL;
// Make the new node the head
new_node->next = *head_ref;
// Change prev of current head to new node
if (*head_ref != NULL) {
(*head_ref)->prev = new_node;
}
// Update the head reference
*head_ref = new_node;
}
int main() {
Node* head = NULL;
insertAtBeginning(&head, 5);
insertAtBeginning(&head, 4);
insertAtBeginning(&head, 3);
// Print the list (forward traversal)
Node* temp = head;
while (temp != NULL) {
std::cout << temp->data << " ";
temp = temp->next;
}
std::cout << std::endl;
// Output: 3 4 5
}
This code inserts nodes 3, 4, and 5 at the beginning of an initially empty list. The output (3 4 5) demonstrates the successful forward traversal.
Explanation
- A new node is created with the provided data, and its prev pointer is set to NULL (since it's the new head).
- The next pointer of the new node points to the current head.
- If the list wasn't empty, the prev pointer of the existing head is updated to reference the new node.
- Finally, the head reference is updated to point to the newly inserted node.
Insertion at the End
The accompanying C++ code adds nodes to the end of a doubly linked list program in data structure and then prints it. Here's a breakdown of the code and what it produces:
C++
void insertAtEnd(Node** head_ref, int new_data) {
// Allocate memory for a new node
Node* new_node = new Node;
new_node->data = new_data;
// Handle the empty list case
if (*head_ref == NULL) {
new_node->prev = NULL;
new_node->next = NULL;
*head_ref = new_node;
return;
}
// Traverse to the last node
Node* last = *head_ref;
while (last->next != NULL) {
last = last->next;
}
// Update last node's next and new node's prev
last->next = new_node;
new_node->prev = last;
new_node->next = NULL; // Since it's the last node
}
int main() {
Node* head = NULL;
insertAtEnd(&head, 5);
insertAtEnd(&head, 10);
insertAtEnd(&head, 15);
// Print the list (forward traversal)
Node* temp = head;
while (temp != NULL) {
std::cout << temp->data << " ";
temp = temp->next;
}
std::cout << std::endl;
// Output: 5 10 15
}
This code inserts nodes 5, 10, and 15 at the end of an initially empty list. The output (5 10 15) confirms successful insertion.
Explanation
- A new node is created with the provided data.
- The new node becomes the head and tail (prev and next are NULL) if the list is empty.
- Otherwise, we traverse the list to find the last node.
- The new node is pointed to by updating the previous node's next pointer.
- The final node is indicated by the previous pointer of the new node.
- The next pointer of the new node is set to NULL, as it's now the last node.
Deletion at the Beginning
The accompanying C++ code specifies the deleteAtBeginning function. If removes the first node from a doubly linked list. It also shows how it is used in the main function. Here's a breakdown of the code and the intended results:
C++
void deleteAtBeginning(Node** head_ref) {
// Handle empty list case
if (*head_ref == NULL) {
return;
}
// Store the head node
Node* temp = *head_ref;
// Update head reference if there's more than one node
if (temp->next != NULL) {
temp->next->prev = NULL;
*head_ref = temp->next;
} else {
// If it's the only node, set head to NULL
*head_ref = NULL;
}
// Deallocate memory of the deleted node
delete temp;
}
int main() {
Node* head = NULL;
insertAtBeginning(&head, 5);
insertAtBeginning(&head, 4);
insertAtBeginning(&head, 3);
deleteAtBeginning(&head);
// Print the list (forward traversal)
Node* temp = head;
while (temp != NULL) {
std::cout << temp->data << " ";
temp = temp->next;
}
std::cout << std::endl;
// Output: 4 5
}
This code deletes the first node (value 3) from the list. The output (4 5) shows the successful deletion.
Explanation
- We check if the list is empty. If so, there's nothing to delete.
- A temporary pointer stores the head node.
- If there's more than one node, the next pointer of the second node is updated to point to NULL (as it becomes the new head). The head reference is also updated to point to the second node.
- If there's only one node (head), the head reference is set to NULL.
- Finally, the memory associated with the deleted node is deallocated using delete.
Deletion at the End
The accompanying C++ code provides the deleteAtEnd function. It removes the last node from a doubly linked list data structure and shows how it is used in the main function. Here's a breakdown of the code and the intended results:
C++
void deleteAtEnd(Node** head_ref) {
// Handle empty list case
if (*head_ref == NULL) {
return;
}
// Traverse to the last node
Node* last = *head_ref;
while (last->next != NULL) {
last = last->next;
}
// Handle deletion of the only node
if (last == *head_ref) {
*head_ref = NULL;
} else {
// Update the prev pointer of the second-last node
last->prev->next = NULL;
}
// Deallocate memory of the deleted node
delete last;
}
int main() {
Node* head = NULL;
insertAtEnd(&head, 5);
insertAtEnd(&head, 10);
insertAtEnd(&head, 15);
deleteAtEnd(&head);
// Print the list (forward traversal)
Node* temp = head;
while (temp != NULL) {
std::cout << temp->data << " ";
temp = temp->next;
}
std::cout << std::endl;
// Output: 5 10
}
Use code with caution.
This code removes the last node (value 15) from the list. The output (5 10) verifies the deletion.
Explanation:
- We check if the list is empty. If so, there's nothing to delete.
- We traverse to the last node.
- If there's only one node (head), the head reference is set to NULL.
- Otherwise, the next pointer of the second-last node is updated to NULL (effectively removing the last node from the list).
- The memory associated with the deleted node is deallocated using delete.
Traversal Techniques
Doubly linked lists allow for traversing the list in both directions due to the prev pointer:
Forward Traversal
The provided C++ code snippet iterates through a doubly linked list program in data structure and prints the data of each node. Here's a breakdown of what the code does:
C++
Node* temp = head;
while (temp != NULL) {
// Access data in temp
std::cout << temp->data << " ";
temp = temp->next;
}
This code iterates through the list, starting from the head node. It prints the data in each node (temp->data) until it reaches the end (indicated by a NULL next pointer).
Reverse Traversal
The provided C++ code snippet iterates through a doubly linked list in data structure program. It then prints the data of each node, but this time in reverse order. Here's a breakdown of what the code does:
C++
Node* temp = *head_ref; // Assuming we have a tail pointer
while (temp != NULL) {
// Access data in temp
std::cout << temp->data << " ";
temp = temp->prev;
}
This code starts from the last node (assuming we have a tail pointer) and iterates backward. It accesses data and moves to the prev node until it reaches the head node (indicated by a NULL prev pointer).
Searching and Accessing Elements
There are two primary ways to search for elements in a doubly linked list:
Linear Search
We iterate through the list, comparing the data in each node with the search key. If a match is found, we return the node or its position.
C++
Node* search(Node* head, int key) {
Node* temp = head;
while (temp != NULL) {
if (temp->data == key) {
return temp;
}
temp = temp->next;
}
return NULL; // Search key not found
}
Use code with caution.
Explanation
The search function takes the head of the list and the search key as input. It iterates through the list, comparing the data in each node with the key. If a match is found, the function returns a pointer to that node. Otherwise, it returns NULL if the key is not present.
Random Access
Random access is accessing an element based on its position. It is less efficient in doubly linked lists than it is in arrays. You would need to go through the list from beginning to end until you reach the desired location and access the element's contents. This strategy may be less efficient for frequent random access operations.
Doubly Linked List in Data Structure Program Variants
There are variations of the basic doubly linked list in data structure program that offer specific advantages:
Circular Doubly Linked Lists
The final node's next pointer in a circular doubly linked list points back to the head node. This forms a closed loop in the list. This structure can be useful for applications like implementing a round-robin scheduler.
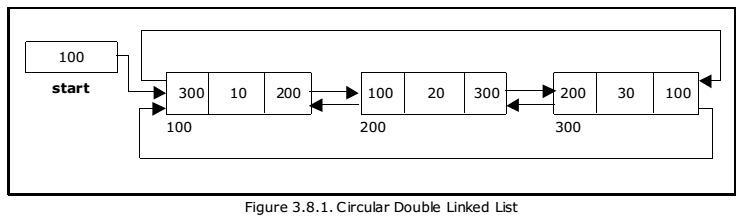
Sentinel Node Doubly Linked Lists
A closed loop is created in a circular doubly linked list data structure when the final node's next pointer points back to the head node. This structure can be useful for tasks such as building a round-robin scheduler or depicting a continuous flow.
Doubly Linked List: Common Mistakes to Avoid
While doubly linked lists offer advantages, there are pitfalls to be aware of:
1. Memory Leaks
Failure to deallocate memory after removing nodes from the list can result in memory leaks. This happens because the memory utilized by the removed node is still allocated but inaccessible to your software.
Solution: Always use delete (or related functions in other languages) to free memory associated with removed nodes after updating pointers during deletion operations.
Here's a doubly linked list example of a memory leak:
C++
void deleteNode(Node* delNode) {
// Incorrect implementation (memory leak)
// delNode is removed from the list structure, but its memory isn't deallocated
// ... (list manipulation code)
}
2. Incorrect Pointers
Mistakes in managing pointers might result in unexpected behavior or crashes. Common issues are:
- Dangling Pointers: They point to memory that has been deallocated, which results in access violations.
- Unintended Modifications: If you incorrectly modify the pointers, the list's structure can break.
Solution: Handle pointer updates carefully while inserting, deleting, and traversing. Double-check your reasoning to ensure that pointers appropriately reflect the list's structure. Tools such as debuggers and print statements are used to visually represent pointer values during development.
Here's an doubly linked list example of incorrect pointer modification:
C++
void insertAtEnd(Node** head_ref, int new_data) {
// Incorrect implementation (may break the list)
Node* new_node = new Node;
new_node->next = NULL;
// This should point to the last node, but it's left unassigned
new_node->prev = NULL;
*head_ref = new_node; // This makes the new node the head, potentially breaking the list if there were existing nodes
}
By understanding these common mistakes and following best practices, you can work with doubly linked lists and avoid potential issues in your code.
Comparisons with Other Data Structures
Comparison with Single Linked Lists
- Lists with double linking: Permit traversals both forward and backward. Because of the extra prior pointer, the implementation is more difficult.
- Single Linked Lists: Only allow for forward traversal. Simpler to implement but lack the flexibility of backward traversal.
Comparison with Arrays
- Doubly Linked Lists: They are dynamic in size, meaning nodes can be added or removed at any point. They are not suitable for random access operations due to the need for traversal.
- Arrays: Fixed size, offering efficient random access (accessing elements by index). It is not suitable for frequent insertions or deletions, as resizing can be expensive.
Conclusion/Wrapping Up
Doubly linked list data structures are functional data structures useful for scenarios that demand forward and backward traversals. Understanding the essential ideas, operations, and trade-offs of doubly linked lists compared to other data structures will allow you to use them effectively in your programming activities.
FAQs
1. What is the structure declaration of a doubly linked list?
The structure declaration includes fields for data and two pointers (prev and next). It refers to the previous and next nodes in the list.
2. Is a doubly linked list a unidirectional data structure?
No, a doubly linked list data structure is bidirectional. Because the previous pointer is present, you can navigate the list both forward and backward.
3. What is a doubly circular linked list in data structure?
A closed loop is created in a circular doubly linked list data structure when the final node's next pointer points back to the head node.
4. What is a doubly linked list also called?
Doubly linked lists are also sometimes called two-way lists. This name highlights their key characteristics. Each node in the list has pointers to both the previous and the next node. It makes for efficient traversal in both forward and backward directions.
5. What are the 4 types of linked lists?
Common linked list types include: Singly linked list (one pointer per node)Doubly linked list (two pointers per node)Circular linked list (end connects back to beginning)Singly/doubly circular linked list (combination of previous types) Singly linked list (one pointer per node) Doubly linked list (two pointers per node) Circular linked list (end connects back to beginning) Singly/doubly circular linked list (combination of previous types)
6. What is the application of a doubly linked list?
Doubly linked lists are useful when frequent insertions/deletions from both ends or two-way traversal are required. Application of doubly linked list examples include: LRU cache implementationUndo/redo functionalityMusic playlists (allowing previous/next song) LRU cache implementation Undo/redo functionality Music playlists (allowing previous/next song)
7. What are the advantages of a doubly linked list?
Efficient insertion/deletion at any positionSupports both forward and backward traversal Efficient insertion/deletion at any position Supports both forward and backward traversal
8. What are the three parts of a doubly linked list?
Each node in a doubly linked list data structure typically has three parts: Data field (stores the information)prev pointer (points to the previous node)next pointer (points to the next node) Data field (stores the information) prev pointer (points to the previous node) next pointer (points to the next node)

Author|309 articles published





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
Disclaimer
The above statistics depend on various factors and individual results may vary. Past performance is no guarantee of future results.
The student assumes full responsibility for all expenses associated with visas, travel, & related costs. upGrad does not .