All courses
Agentic AI
Agentic AI

IIIT Bangalore
Executive Programme in Generative AI for LeadersArtificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership ProgrammeIIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, SwitzerlandGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsMBA
Masters

Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Executive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
Offline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)Paris School of Business
Master of Science in Business Management and Technology
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIIT-B & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
- uGSOT - B.Tech
More



14. Radix Sort
20. AVL Tree
21. Red-Black Tree
23. Expression Tree
24. Adjacency Matrix
36. Greedy Algorithm
42. Tower of Hanoi
43. Stack vs Heap
47. Fibonacci Heap
49. Sparse Matrix
50. Splay Tree
Understanding Tree Traversal in Data Structures
Introduction
Tree traversal involves the systematic inspection of every node in a tree data structure to validate or update data. This fundamental operation has been used extensively and can be found in many different domains.
When you traverse a tree, you visit every node within its structure. Whether adding up all values in the tree or looking for the biggest one, each requires going through all the nodes.
In this guide, we will explore the complexities of tree traversal in data structure, offering clear explanations and insightful examples.
Overview
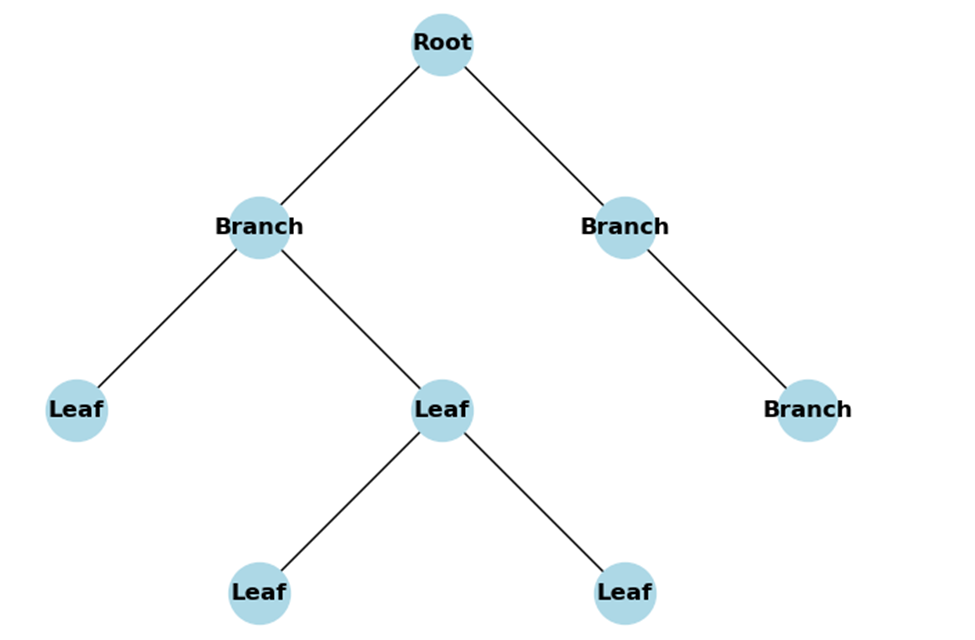
Trees are among numerous data structures that stand out in terms of versatility and power. Their hierarchical organization and branching structures make them basic building blocks for many applications in computer science, but understanding how to traverse them efficiently is vital if their true potential is to be realized.
This guide will begin with an overview of tree data structures, including definitions of key terms. It will then cover tree traversal methods, their applications, and relevant algorithms.
What is the Tree Data Structure?
The tree data structure is a basic concept in computer science, which signifies the hierarchical relationship between elements. Think of it as a family tree where each person (or node) can have children (or branches) coming out from them. In trees, nodes are linked by edges, forming paths from the root node (the highest point) to leaf nodes (without children).
Some important terms include:
- Root: The highest point at which all other points originate.
- Leaves: The endpoints without any children.
- Branches: The connecting links between nodes.
- Depth: The level of a node in the tree measured from the root.
How Does Tree Traversal Work?
Tree traversal in the data structure is a fundamental computer science operation that involves visiting every node of the tree exactly once. It starts at one node (the root) and ends at another. It also goes through branches of trees, examining each node as it carries out specific functions like accessing or changing data, searching for particular items, or representing the tree.
Two primary data structures used for tree traversal are:
Stack Data Structure: Operates on the principle of Last-In-First-Out (LIFO), where elements are added and removed.
Queue Data Structure: Operates based on the First-In-First-Out (FIFO) principle, where objects are added and withdrawn in linear data sets.
Now, let us consider an example to illustrate how tree traversal works:
Consider tree traversals as if you want to go through a maze made up of trees. Imagine yourself standing among trees all around everywhere. Each individual tree represents a unique data structure whose roots comprise several nodes containing valuable details. Your objective is to navigate through this intricate network of nodes, systematically examining each one to discover what lies within its depths.
Types of Tree Traversal Algorithms
When it comes to traversing trees, you have quite a few options for which algorithms you can use, each unique in its strengths and purposes. Let’s now explore the types of these algorithms:
1. Depth First Search or DFS
DFS is an algorithm used for traversing or searching trees and graphs generally. The algorithm begins at a specified root node in DFS and explores as far as possible before backtracking along each branch.
DFS has several characteristics, including
Exploration of Depth-First: DFS examines depth within a tree or graph organization before moving on to nearby nodes. This means that once one branch is completely examined, the algorithm will consider the other.
Stack-Based Implementation: In many cases, DFS uses stacks, a data structure that records points to follow. This operation allows for efficient movement back when required.
Non-Optimality: Even though DFS ensures the exploration of all nodes in a graph or tree, it does not guarantee the shortest path search among others. Depending on the problem, additional mechanisms might need to be implemented before DFS can achieve optimality.
Now that we've defined DFS let's explore some specific types of DFS traversal algorithms that utilize this fundamental approach.
(i) Inorder Traversal
In Inorder traversal, The left subtree is visited first, then the root node, and finally, the right subtree is visited. This traversal method is common in Binary Search Trees (BSTs) to extract sorted elements.
Here's the implementation for inorder traversal in Java programming language
public void inorderTraversal(TreeNode root) {
if (root != null) {
inorderTraversal(root.left);
System.out.print(root.data + " ");
inorderTraversal(root.right);
}
}
Let's consider an example of a binary search tree:
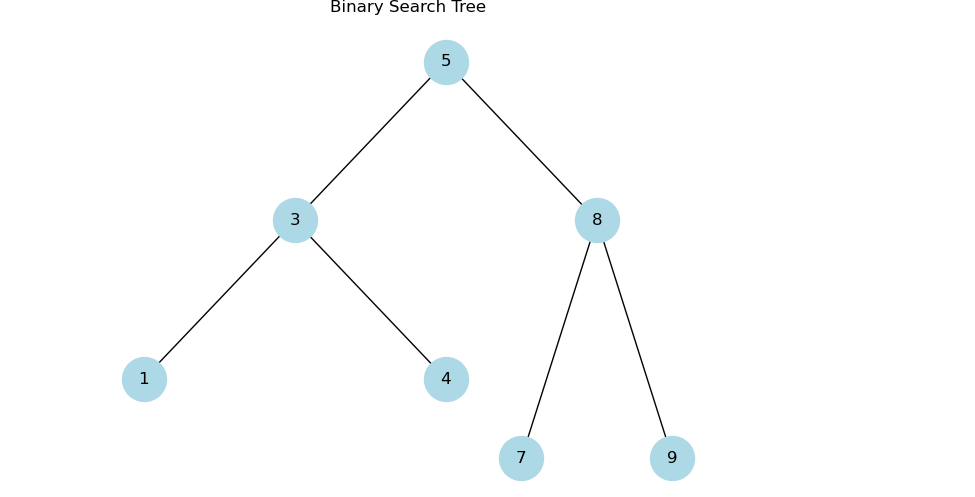
When performing an inorder traversal on this tree, the order of visited nodes would be 1, 3, 4, 5, 7, 8, 9.
(ii) Preorder Traversal
Preorder traversal starts from visiting the root node before moving to traverse its left subtree and finally the right subtree. It is useful for building a copy of a tree or prefix expressions.
Here's the implementation for preorder traversal in Java:
public void preorderTraversal(TreeNode root) {
if (root != null) {
// Print the data of the current node
System.out.print(root.data + " ");
// Traverse the left subtree recursively
preorderTraversal(root.left);
// Traverse the right subtree recursively
preorderTraversal(root.right);
}
}
Let's use the same example tree:

Performing a preorder traversal on this tree would yield the order: 5, 3, 1, 4, 8, 7, 9.
(iii) Postorder Traversal
In postorder traversal, after visiting both the left and right subtrees, visit a parent element as well. In expression trees, this type of traversal method is frequently used in evaluating postfix expressions.
Using the same example tree:
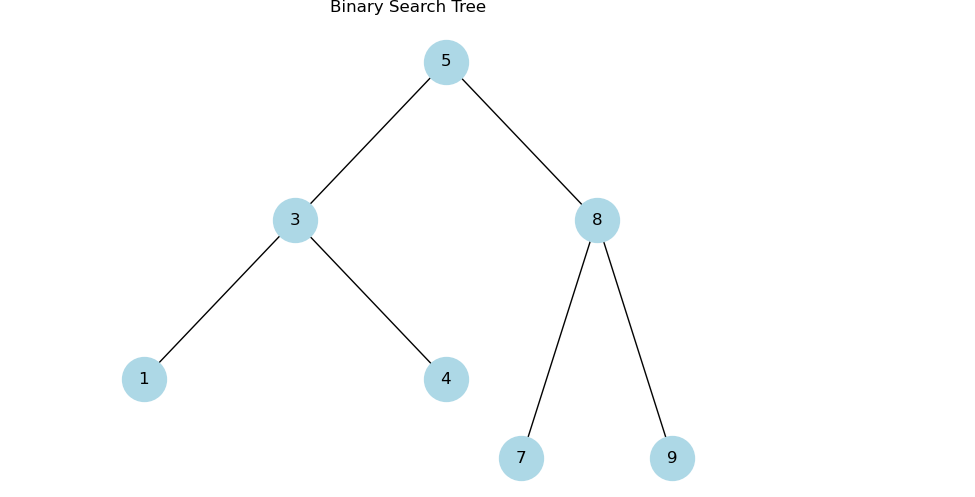
A postorder traversal of this tree would result in the order: 1, 4, 3, 7, 9, 8, 5.
2. Breadth-first search (BFS) or Level Order Traversal
Level Order Traversal, also called Breadth First Search (BFS), is one of the basic tree traversal algorithms that explores the levels of the tree level by level and visits each node at every level before moving on to the next level.
Consequently, BFS visits all nodes at a given level one after another from left to right until they are completed; it then proceeds to another level containing other nodes within it. The algorithm guarantees that nodes will be visited according to their distance from the root node by examining them on each level of the tree.
This approach ensures that nodes are walked in the order of their distances from the root node, which is very helpful when finding the shortest path in a graph and searching for nearest neighbors in a network.
Below is the Java implementation of Level Order Traversal (Breadth First Search or BFS)
import java.util.LinkedList;
import java.util.Queue;
public void levelOrderTraversal(TreeNode root) {
if (root == null) {
return;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
while (!queue.isEmpty()) {
TreeNode node = queue.remove();
System.out.print(node.data + " ");
if (node.left != null) {
queue.add(node.left);
}
if (node.right != null) {
queue.add(node.right);
}
}
}
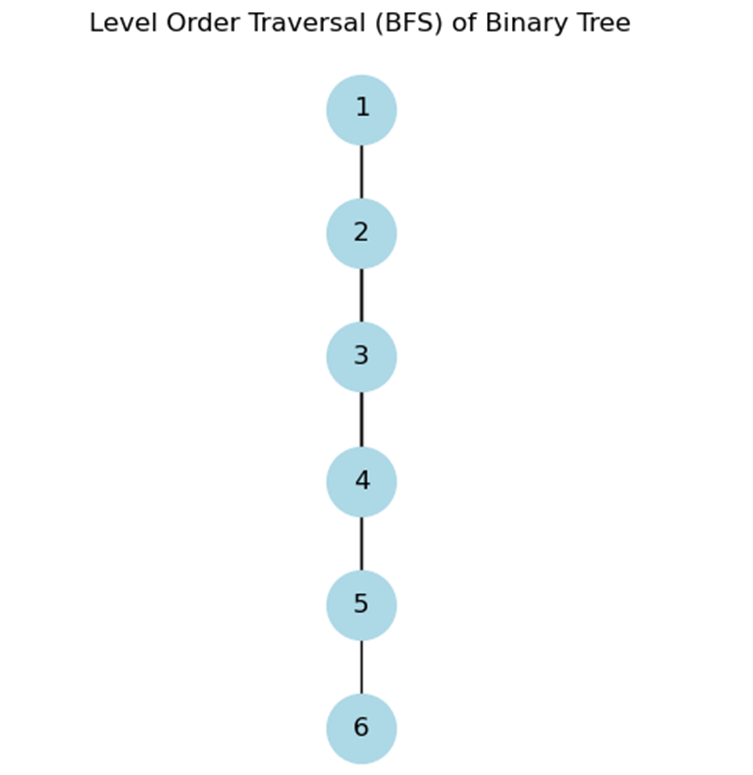
Let's consider an example of a binary tree:
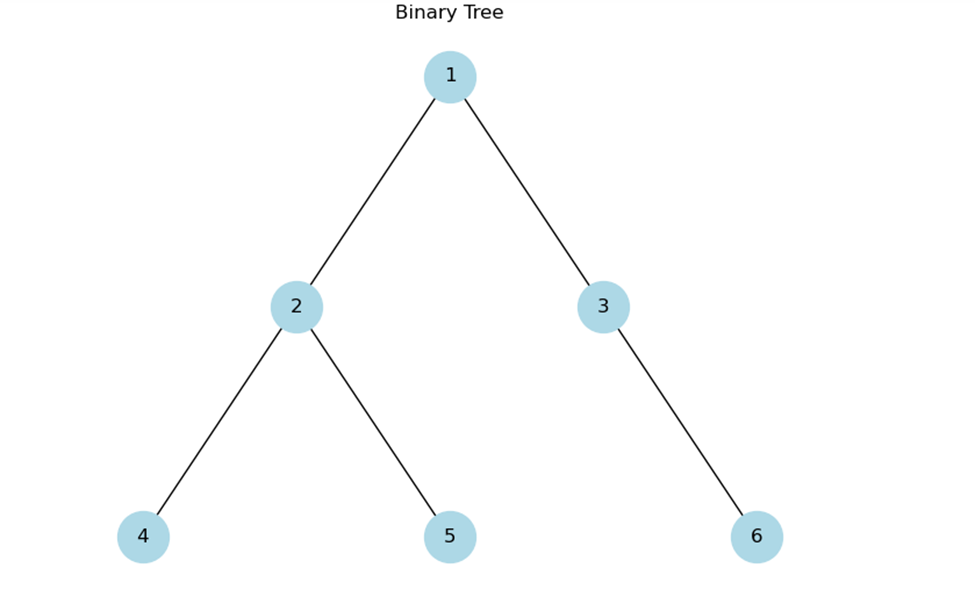
Performing a level order traversal on this tree would visit the nodes in the order: 1, 2, 3, 4, 5, 6.
Nodes at each level are visited before proceeding to the next level. So you have the following output:
3. Boundary Traversal
Boundary Traversal is another way to traverse through all leaf nodes and the left boundary and right boundary of a Tree. This traversal method comes in handy for various tasks where you need to operate upon the outermost nodes of the tree, like printing them or doing some computation, etc.
Here’s the Java code implementation for the Boundary traversal
class TreeNode {
int val;
TreeNode left, right;
public TreeNode(int val) {
this.val = val;
left = right = null;
}
}
public class BoundaryTraversal {
// Function to perform boundary traversal of a binary tree
public void boundaryTraversal(TreeNode root) {
if (root != null) {
System.out.print(root.val + " ");
printLeftBoundary(root.left);
printLeaves(root.left);
printLeaves(root.right);
printRightBoundary(root.right);
}
}
// Function to print the left boundary of a binary tree
private void printLeftBoundary(TreeNode node) {
if (node == null || (node.left == null && node.right == null))
return;
System.out.print(node.val + " ");
if (node.left != null)
printLeftBoundary(node.left);
else
printLeftBoundary(node.right);
}
// Function to print the right boundary of a binary tree
private void printRightBoundary(TreeNode node) {
if (node == null || (node.left == null && node.right == null))
return;
if (node.right != null)
printRightBoundary(node.right);
else
printRightBoundary(node.left);
System.out.print(node.val + " ");
}
// Function to print the leaf nodes of a binary tree
private void printLeaves(TreeNode node) {
if (node == null)
return;
if (node.left == null && node.right == null)
System.out.print(node.val + " ");
printLeaves(node.left);
printLeaves(node.right);
}
}
Consider a binary tree:
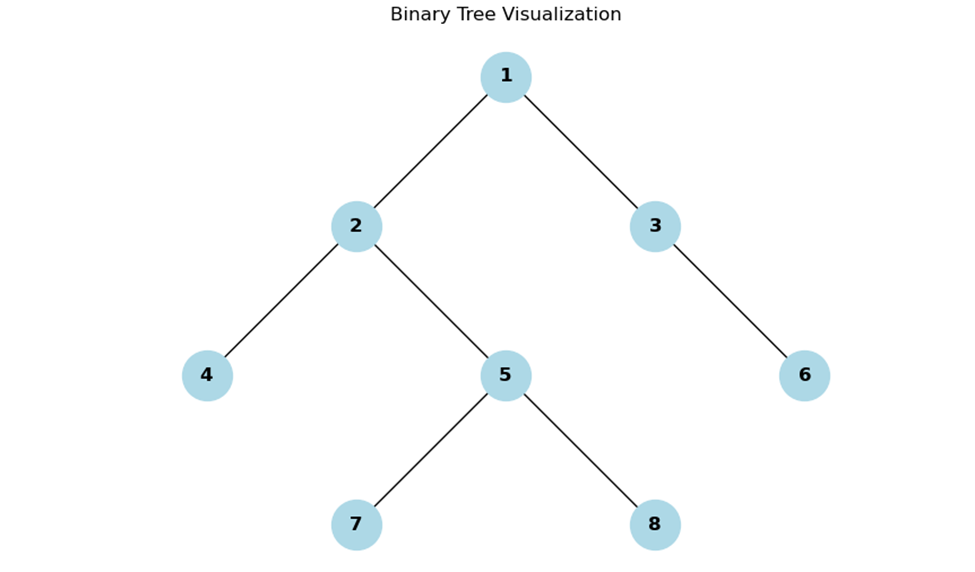
Boundary Traversal of this tree would visit the nodes in the order: 1, 2, 4, 7, 8, 5, 3, 6.
This traversal strategy is valuable in scenarios where you need to process or analyze the boundary nodes of a tree, such as generating a boundary representation of the tree
4. Diagonal Traversal
Diagonal Traversal involves traversing the tree diagonally, starting from the root down to the right, while visiting the diagonal nodes. In contrast to other methods of traversing, where we go over each node according to its hierarchical position, diagonal traversal does this more subtly by capturing inter-diagonal relationships.
Here is the Java implementation for diagonal traversal
import java.util.*;
public class TreeNode {
int data;
TreeNode left, right;
public TreeNode(int data) {
this.data = data;
left = right = null;
}
}
public class DiagonalTraversal {
public void diagonalTraversal(TreeNode root) {
if (root == null)
return;
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
while (!queue.isEmpty()) {
TreeNode curr = queue.poll();
while (curr != null) {
System.out.print(curr.data + " ");
if (curr.left != null)
queue.add(curr.left);
curr = curr.right;
}
}
}
Consider the same binary tree as before:
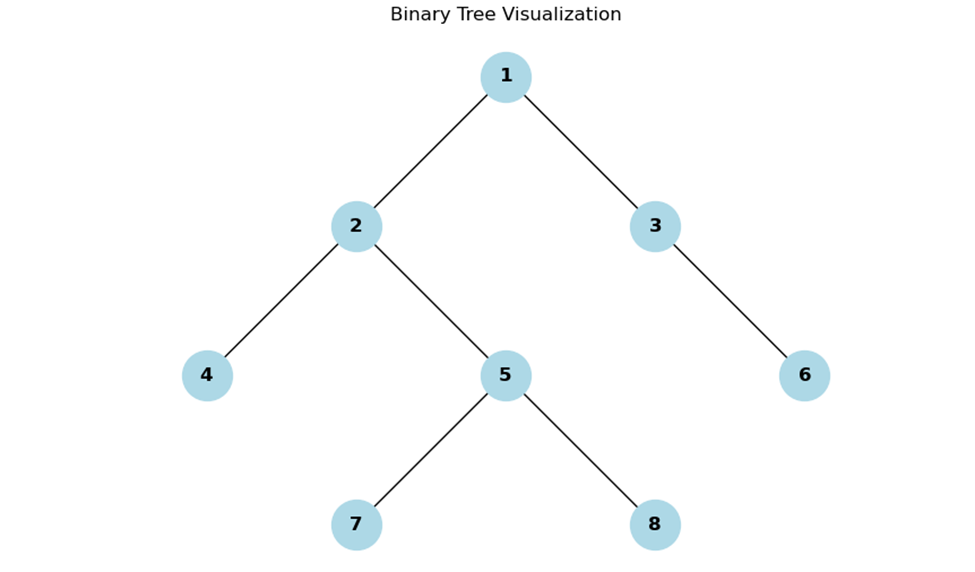
Diagonal Traversal of this tree would visit the nodes in the order: 1, 3, 6, 2, 5, 8, 4, 7.
Applications of Tree Traversal
Tree Traversal has a variety of uses in computer science and other fields. Some major applications of tree traversal include:
1. Binary Search Trees (BST)
The traversal of trees is an important part of binary Search Trees (BST), which are employed widely in databases, file systems, and searching algorithms. By doing this, one can find data efficiently using binary search tree traverTree traversal algorithms, which have been used to implement both search and sorting operations.
2. Expression Trees
In compiler design and mathematical expression evaluation, the use of binary tree traversal in data structure is evident in expression trees. You can evaluate mathematics expressions or generate equivalent codes more effectively by doing pre-order, post-order, or in-order traversal on an expression tree.
For example, if you were developing a compiler for a programming language that supported mathematical expressions. Postorder traversing an expression tree representing the mathematical expression could be used to generate machine-readable code for efficient execution concerning the same.
3. Graph Traversal
A tree traversal algorithm in data structure is essential for graph traversal algorithms. Among them, Tree Traversal techniques like depth-first search (DFS) and breadth-first search (BFS), derived from tree traversal, are widely adopted in graph theory research, including connected component finding, cycle detection, and graph problem-solving.
4. File Systems
Tree traversal algorithms are used to handle directory structures in file systems, list files, and perform file operations.
For example, when you use a file explorer to find a file on your computer, the underlying file system uses tree traversal algorithms that pass along the directory structure to access the specified file and provide information about its location and properties.
5. Game Development
Pathfinding, spatial partitioning, and behavior tree processing are some areas where tree traversal algorithms come into play in the game development industry. Game developers can employ DFS or BFS to move through their game maps, detect barriers that prevent players from getting to other points of interest, and increase overall optimization.
Conclusion
To sum up, tree traversal in data structures is a basic concept in computer science. It provides multiple ways of efficiently walking through and examining trees. Traversal algorithms can be used to analyze graph structures and manage file systems, among other things.
This guide has explored the complexities of tree traversal. It has covered basic concepts in tree data structures and examined different traversal algorithms, including DFS, BFS, boundary condition methods, and diagonal traversals. Understanding tree traversal algorithms and their applications provides valuable insights for working with tree structures, facilitating innovation, and problem-solving in various projects.
FAQs
1. What is the traversal of a binary tree?
Traversing a binary tree means that the process must cover every node exactly once. Therefore, it involves exploring the tree's structure in an orderly manner, either from top to bottom (Depth First) or left to right for each level (Breadth First). What are the different types of traversing in data structure?
2. What are the different types of traversing in data structure?
In data structures, there are several kinds of traversal. Depth-first search(Inorder traversal, Preorder traversal, and Postorder traversal)Level order traversal (Breadth-First Search)Diagonal TraversalBoundary Traversal Depth-first search(Inorder traversal, Preorder traversal, and Postorder traversal) Level order traversal (Breadth-First Search) Diagonal Traversal Boundary Traversal What is the inorder traversal of a tree?
3. What is the inorder traversal of a tree?
Inorder traversal involves visiting the subtree on the left first, then the root node, and lastly the right subtree. This kind of traversing is often used in binary search trees to retrieve elements in sorted order. What is Postorder traversal in data structure?
4. What is Postorder traversal in data structure?
Postorder traversing implies visiting the left and right subtrees before reaching the root node. It applies when working with expression trees to evaluate postfix expressions. What is the traversal of graph and tree?
5. What is the traversal of graph and tree?
When one speaks about graphs or trees’ way of crossing, this refers to the systematic visiting of each vertex or node within them. It occurs by navigating around a particular order aimed at doing things like searching, sorting, or evaluating as well. What is an AVL tree in data structure?
6. What is an AVL tree in data structure?
An AVL tree is a self-balancing binary search tree with no more than one difference in height between two child subtrees of the same node. This ensures the tree remains balanced, making it optimal for searches, insertions, and deletions. What do you mean by traversal?
7. What do you mean by traversal?
Traversal involves more than visiting each element or node in a data structure one after the other in some standardized order. It is about going through the structure to achieve tasks like accessing, searching, or modifying data.

Author|309 articles published





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
Disclaimer
The above statistics depend on various factors and individual results may vary. Past performance is no guarantee of future results.
The student assumes full responsibility for all expenses associated with visas, travel, & related costs. upGrad does not .