For working professionals
For fresh graduates
- Study abroad
More
- Post Graduate Certificate in Data Science & AI (Executive)
- Gen AI Foundations Certificate Program from Microsoft
- Gen AI Mastery Certificate for Data Analysis
- Gen AI Mastery Certificate for Software Development
- Gen AI Mastery Certificate for Managerial Excellence
- Gen AI Mastery Certificate for Content Creation
- Post Graduate Certificate in Product Management from Duke CE
- Human Resource Analytics Course from IIM-K
- Global Master Certificate in Integrated Supply Chain Management
- Gen AI Foundations Certificate Program from Microsoft
- CSM® Certification Training
- CSPO® Certification Training
- PMP® Certification Training
- SAFe® 6.0 Product Owner Product Manager (POPM) Certification
- Post Graduate Certificate in Product Management from Duke CE
- Professional Certificate Program in Cloud Computing and DevOps
- Python Programming Course
- Executive Post Graduate Programme in Software Dev. - Full Stack
- AWS Solutions Architect Training
- AWS Cloud Practitioner Essentials
- AWS Technical Essentials
- The U & AI GenAI Certificate Program from Microsoft
14. Radix Sort
20. AVL Tree
21. Red-Black Tree
23. Expression Tree
24. Adjacency Matrix
36. Greedy Algorithm
42. Tower of Hanoi
43. Stack vs Heap
47. Fibonacci Heap
49. Sparse Matrix
50. Splay Tree
What is the Trie Data Structure? Explained with Examples
Introduction
Trie, pronounced as "try," is a versatile tree-based data structure that efficiently stores and retrieves a dynamic set of strings. From auto-completion to spell-checking and beyond, Trie finds applications in various domains where efficient string manipulation is crucial. In this blog, we will delve into the concepts, properties, implementation, and applications of the Trie data structure.
Overview
Trie offers efficient retrieval operations such as search and prefix search, typically with near-constant time complexity. However, its space efficiency may vary depending on the number of words and the alphabet size. Nevertheless, Trie remains a powerful tool for handling strings efficiently, making it invaluable in various applications requiring rapid string manipulation and retrieval.
What is Trie?
Trie, also known as a Prefix Tree, is a tree-like data structure in which each node represents a single character of a string. The root node displays an empty string, and each path, from the root to the leaf node creates a complete string. Trie is adept at storing and retrieving strings efficiently, especially when common prefixes exist among them.
Structure of Trie
At its core, a Trie algorithm comprises nodes, each containing pointers to its child nodes and an optional marker indicating the end of a valid word. By leveraging shared prefixes among words, Trie achieves efficient storage and retrieval of strings while minimizing memory usage.
Basic Operations
Trie supports fundamental operations crucial for managing strings:
- Insertion: Insert a key (string) into the Trie.
- Search: Search for a key (string) in the Trie.
- Deletion: Remove a key from the Trie.
These operations empower Trie to handle a wide array of tasks involving strings efficiently.
Insertion in Trie Data Structure
Here is a Python implementation of insertion in a Trie tree data structure:
class TrieNode:
def __init__(self):
self.children = {} # Dictionary to store child nodes
self.is_end_of_word = False # Flag to indicate end of a word
class Trie:
def __init__(self):
self.root = TrieNode() # Initialize Trie with an empty root node
def insert(self, word):
current = self.root # Start insertion from the root
for char in word:
# If the current character is not in the children of the current node, create a new node for it
if char not in current.children:
current.children[char] = TrieNode()
# Move to the child node corresponding to the current character
current = current.children[char]
# Mark the last node as the end of the word
current.is_end_of_word = True
# Example usage:
trie = Trie()
words = ["apple", "banana", "orange", "app", "apps"]
for word in words:
trie.insert(word)
This code defines a Trie data structure with a TrieNode class representing each node in the Trie and a Trie class containing the insertion method insert. The insert method takes a string word as input and inserts it into the Trie by traversing the Trie and creating new nodes as needed for each character of the word. Finally, it marks the last node corresponding to the end of the word.
Searching in Trie Data Structure
Here is a Python implementation of searching in a Trie data structure:
class TrieNode:
def __init__(self):
self.children = {} # Dictionary to store child nodes
self.is_end_of_word = False # Flag to indicate end of a word
class Trie:
def __init__(self):
self.root = TrieNode() # Initialize Trie with an empty root node
def insert(self, word):
current = self.root # Start insertion from the root
for char in word:
# If the current character is not in the children of the current node, create a new node for it
if char not in current.children:
current.children[char] = TrieNode()
# Move to the child node corresponding to the current character
current = current.children[char]
# Mark the last node as the end of the word
current.is_end_of_word = True
def search(self, word):
current = self.root # Start search from the root
for char in word:
# If the current character is not in the children of the current node, the word is not present in the Trie
if char not in current.children:
return False
# Move to the child node corresponding to the current character
current = current.children[char]
# If the last node is marked as the end of a word, the word is present in the Trie
return current.is_end_of_word
# Example usage:
trie = Trie()
words = ["apple", "banana", "orange", "app", "apps"]
for word in words:
trie.insert(word)
print(Trie.search("apple")) # Output: True
print(Trie.search("app")) # Output: False (because "app" is not a complete word)
print(trie.search("banana")) # Output: True
print(trie.search("grape")) # Output: False
In this implementation, the search method of the Trie class takes a string word as input and searches for it in the Trie. It traverses the Trie character by character, starting from the root node. If, at any point, a character is not found in the children of the current node, the method returns False, indicating that the word is not present in the Trie. If the entire word is successfully traversed and the last node is marked as the end of a word, the method returns True, indicating that the word is present in the Trie.
Consider another example:
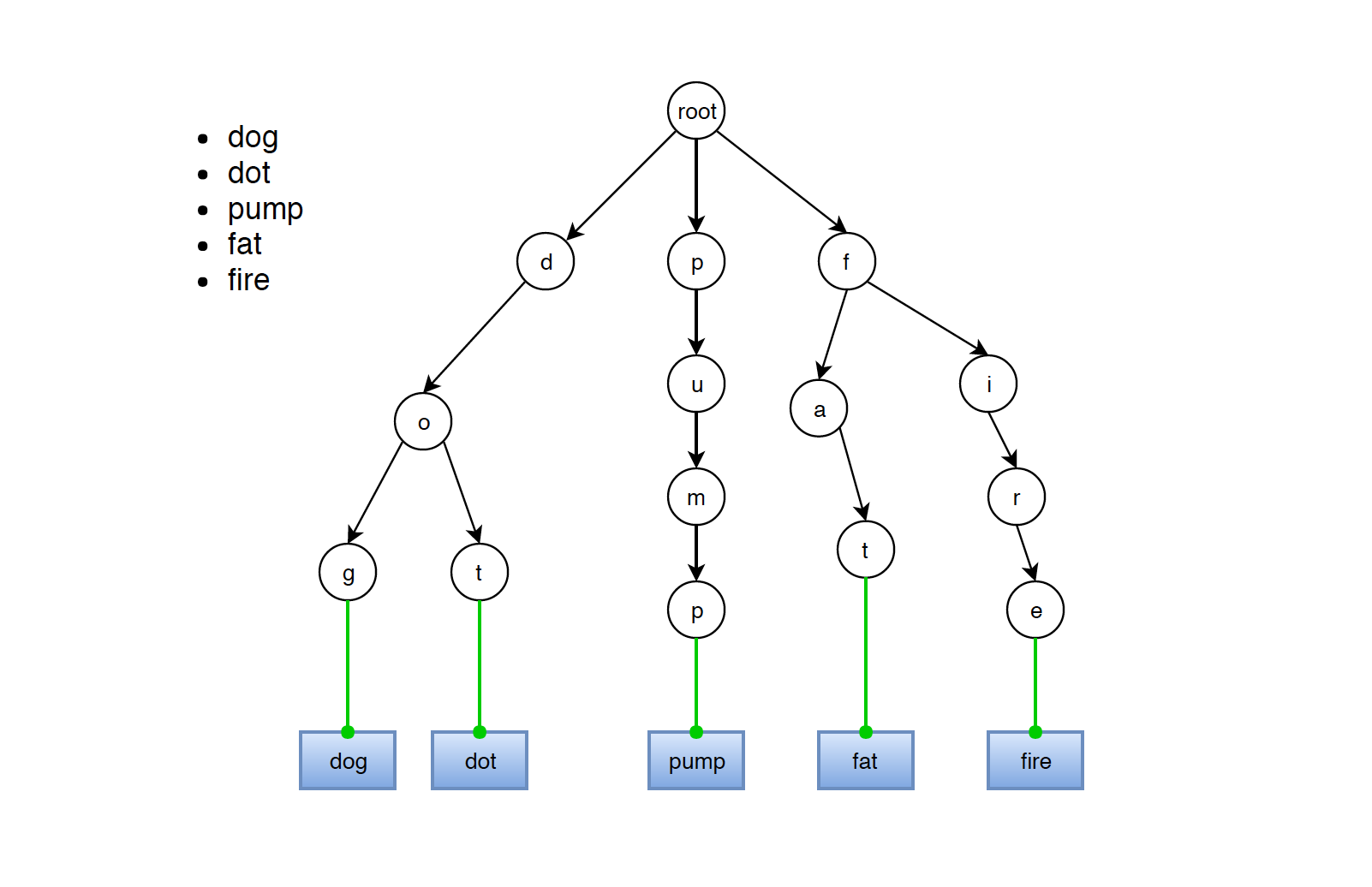
Implementation of Trie
Implementing a Trie involves defining classes for nodes and the Trie itself, along with insertion, search, and prefix search methods. Let us understand the implementation using a Trie data structure example:
class TrieNode:
def __init__(self):
self.children = {}
self.is_end_of_word = False
class Trie:
def __init__(self):
self.root = TrieNode()
def insert(self, word):
current = self.root
for char in word:
if char not in current.children:
current.children[char] = TrieNode()
current = current.children[char]
current.is_end_of_word = True
def search(self, word):
current = self.root
for char in word:
if char not in current.children:
return False
current = current.children[char]
return current.is_end_of_word
def starts_with(self, prefix):
current = self.root
for char in prefix:
if char not in current.children:
return False
current = current.children[char]
return True
# Example usage:
trie = Trie()
words = ["apple", "banana", "orange", "app", "apps"]
for word in words:
trie.insert(word)
print(trie.search("apple")) # Output: True
print(Trie.search("app")) # Output: False (because "app" is not a complete word)
print(trie.starts_with("app")) # Output: True
print(trie.search("banana")) # Output: True
print(trie.search("grape")) # Output: False
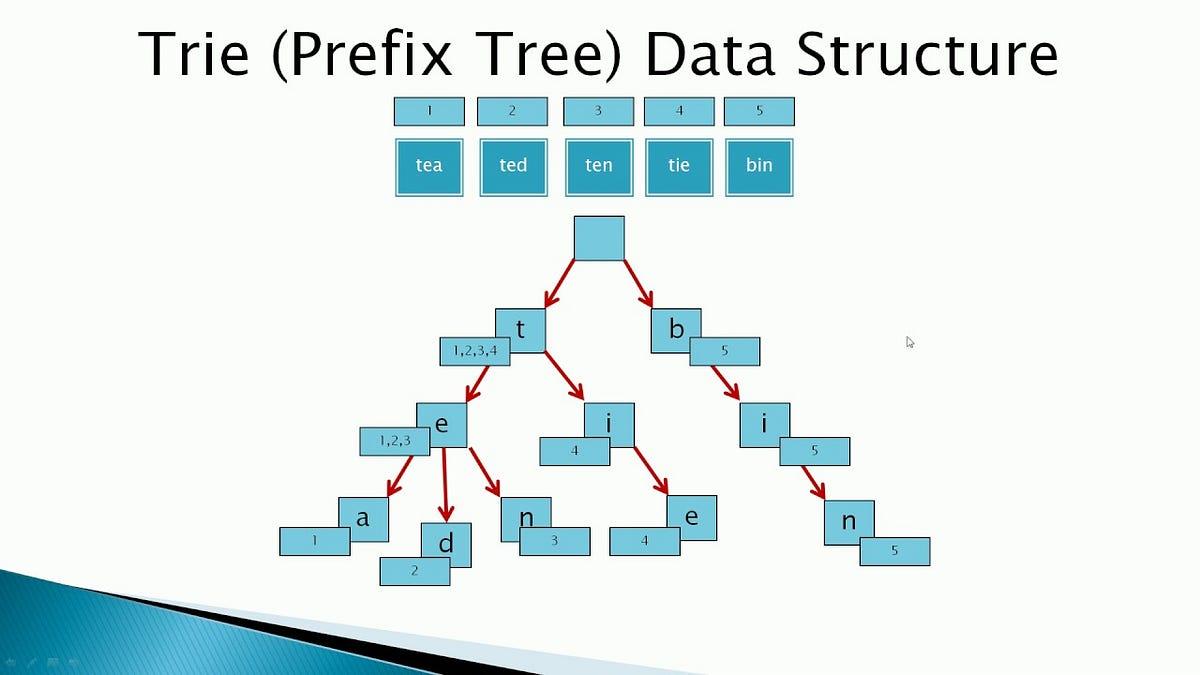
Properties of Trie
Trie possesses several properties that make it a compelling choice for string manipulation:
- Space Efficiency: Trie efficiently stores strings with common prefixes, reducing memory consumption compared to other data structures.
- Time Efficiency: Trie enables fast retrieval operations such as search and prefix search, typically in near-constant time complexity, making it ideal for applications requiring rapid string retrieval.
- Prefix-based Retrieval: Trie supports prefix-based retrieval, which allows for quick suggestions and completions. This makes it invaluable in applications like auto-completion and spell-checking.
Applications of Trie Data Structure
The versatility of Trie extends to various domains, leading to its adoption in numerous applications:
- Auto-completion: Trie facilitates quick suggestions for completing partially typed words by efficiently searching for all words with a given prefix.
- Spell-checking: Trie enables the swift identification of misspelled words by searching for similar words with minor variations, enhancing the accuracy of spell-checking algorithms.
- Dictionary Implementations: Trie provides a space-efficient and fast solution for storing and retrieving dictionary words, making it a cornerstone in dictionary implementations.
- Routing Tables: Trie stores routing information efficiently in networking, aiding in the rapid lookup of destination addresses and route optimization.
Advantages and Limitations
The advantages and limitations of the Trie data structure are given below:
Advantages
- Efficient Retrieval: Trie enables fast retrieval of strings, especially when searching for prefixes or exact matches.
- Space Efficiency: By sharing common prefixes among words, Trie optimizes memory usage, making it suitable for storing large strings.
- Versatility: Trie finds applications in various tasks involving strings, from auto-completion to spell-checking.
Limitations
- Memory Overhead: Trie may consume more than other data structures, especially when dealing with sparse datasets or large alphabets.
- Complexity: While Trie offers efficient retrieval operations, its implementation and maintenance may be more complex than those of simpler data structures like arrays or hash tables.
Final Thoughts
With its efficient storage and retrieval capabilities for strings, Trie stands as a powerful data structure in computer science and software development. By utilizing shared prefixes and optimized traversal, Trie data structure enables swift operations such as search, auto-completion, and spell checking. Understanding the concepts, properties, and applications of Trie uncovers many possibilities for optimizing tasks involving string manipulation and retrieval. As technology continues to evolve, Trie remains a valuable tool in the world of data structures, empowering developers to tackle diverse challenges in string processing with efficiency and elegance.
FAQs
1. What is a Trie in data structure?
Trie is a tree-like data structure used for efficiently storing and retrieving strings. Each node represents a single character and paths from the root to leaf nodes form complete strings.
2. What is a Trie-like data structure?
Trie-like data structure is a tree-based data structure similar to Trie, used for storing and retrieving strings efficiently by hierarchically organizing characters.
3. What are the uses of Trie?
Tries are commonly used in applications like auto-completion, spell-checking, dictionary implementations, and network routing algorithms.
4. Is Trie better than Hashmap?
Whether Trie is better than a HashMap depends on the specific use case. Tries excel at string-related operations like prefix searches, while HashMaps offer constant-time average case performance for key-based operations.
5. What is a Trie also known as?
Trie is also known as the Prefix Tree due to its efficient storage and retrieval of strings based on their prefixes.
6. What is the difference between a tree and a Trie?
The main difference between a tree and a Trie is that while a tree typically stores data in a hierarchical structure, Trie specializes in storing and retrieving strings, with each node representing a character.
7. Is Trie faster than HashMap?
Tries can be faster than HashMaps for certain operations like prefix searches, but HashMaps offer constant-time average case performance for key-based operations, which Trie may not guarantee.
8. What is the difference between hashing and Trie?
Hashing involves mapping keys to indices using a hash function, providing constant-time average case performance for key-based operations. On the other hand, Trie organizes keys in a tree-like structure, allowing efficient string-based operations like prefix searches.
9. What are the disadvantages of Trie?
Trie's disadvantages include increased memory usage, especially for sparse datasets or large alphabets, and potential performance overhead for certain operations compared to simpler data structures like arrays or HashMaps.

Author


upGrad Learner Support
Talk to our experts. We are available 7 days a week, 9 AM to 12 AM (midnight)
Indian Nationals
1800 210 2020
Foreign Nationals
+918068792934
Disclaimer
1.The above statistics depend on various factors and individual results may vary. Past performance is no guarantee of future results.
2.The student assumes full responsibility for all expenses associated with visas, travel, & related costs. upGrad does not provide any a.