All courses
Gen AI & Agentic AI
Gen AI & Agentic AI

IIIT Bangalore
Executive Programme in Generative AI for LeadersArtificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership ProgrammeIIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, SwitzerlandGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIGolden Gate University
DBA in Digital Leadership from Golden Gate University, San FranciscoMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsMasters

Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Executive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)Paris School of Business
Master of Science in Business Management and Technology
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
More
%20(1)-d5498f0f972b4c99be680c2ee3b792d7.svg)




8. BCNF in DBMS
16. Joins in DBMS
17. Indexing In DBMS
21. Deadlock in DBMS
29. B+ Tree
31. Database Schemas
Decomposition in DBMS
ecomposition in a Database Management System (DBMS) involves splitting a table into smaller tables to remove duplicate data and enhance data consistency. This makes the database more organized, efficient, and easier to manage. In other words, decomposition is the act of breaking a relation X into X1, X2,……Xn. This method retains dependencies and doesn't lose any data.
Decomposition in DBMS helps remove duplicate data, errors, and inconsistencies from a database by dividing a table into smaller tables.
What is Normalization?
It is a systematic approach to breaking down tables.
Importance of Normalization in Decomposition
Normalization principles in decomposition are crucial for efficient database design. Here's why:
- Reduces Data Redundancy:
- Organizing data into separate tables saves storage space and improves data consistency.
- Maintains Data Integrity:
- Normalization ensures accurate and consistent data throughout the database.
- Simplifies Data Maintenance:
- Normalized databases are easier to update and less prone to errors.
- Boosts Query Performance:
- Efficient data organization speeds up database queries.
- Eases Database Design:
- Normalization offers a clear structure for easier understanding and expansion.
- In short, normalization is essential in decomposition to create an organized, efficient, and reliable database, leading to better performance and simplified management.
What is Decomposition in DBMS?
Decomposition in DBMS refers to dividing a database table into smaller parts or tables. This process replaces one large table with several smaller ones to organize specific sets of data. It's essential for decomposition to be lossless, ensuring that the original data can be accurately reconstructed from the smaller tables. Improper decomposition can lead to data loss and other issues.
Example: In an E-commerce Inventory Management System, the database holds product details. Breaking down this data into separate tables enhances organization and efficiency by reducing redundancy.
Original Table: Inventory
Product_ID | Product_Name | Quantity | Price |
001 | Laptop | 10 | 800 |
002 | Smartphone | 20 | 500 |
003 | Tablet | 15 | 300 |
Decomposition:
Sub-table 1: Product_Details
Product_ID | Product_Name |
001 | Laptop |
002 | Smartphone |
003 | Tablet |
Sub-table 2: Inventory_Stock
Product_ID | Quantity | Price |
001 | 10 | 800 |
002 | 20 | 500 |
003 | 15 | 300 |
Explanation:
- Product_Details: This table provides detailed information for each product.
- Inventory_Stock: This table details the stock information for each product, distinguishing product identification from its quantity and price.
Types of Decomposition
Decomposition in DBMS mainly comes in two types:
1. Lossless Decomposition:
Ensures we can rebuild the original table accurately from the smaller tables.
Requires a common attribute in the smaller tables.
2. Lossy Decomposition:
May lose some original data when rebuilding the table.
Can create extra, unnecessary data.
Properties of Decomposition
Decomposition in a Database Management System (DBMS) refers to the process of dividing a single table into multiple smaller tables. This is done to enhance data organization, reduce redundancy, and improve database efficiency. To ensure that the database maintains its integrity and reliability post-decomposition, it is essential to adhere to specific properties. Two key properties are:
- Lossless Decomposition Criteria:Lossless decomposition ensures that the original data can be reconstructed accurately from the smaller, decomposed tables. In other words, no information is lost during the decomposition process. To achieve lossless decomposition, the union of the decomposed tables should result in the original table without any loss of data.
- Dependency Preservation:Dependency preservation is another crucial property of decomposition. It ensures that all functional dependencies that held true in the original table (relation) also hold true in the decomposed tables. This means that the relationships between the attributes in the original table are maintained in the smaller tables after decomposition.
In summary, for a decomposition to be considered effective and reliable in DBMS, it should be both lossless and should preserve all the functional dependencies present in the original table.
Exploring Lossless Decomposition
A decomposition is considered lossless if we can reconstruct the original table R by joining the smaller decomposed tables. This method is the preferred choice because it ensures that no information is lost during the decomposition. A lossless join should always produce a result that closely matches the original table.
Key points of Lossless Decomposition:
- The original data should be fully retained when reconstructing the table.
- Combining the smaller tables should yield the exact original table.
Criteria Verification for Lossless Decomposition in DBMS
- Consider a relation Y. If we decompose this relation into sub-relations Y1 and Y2, the decomposition is termed as lossless if it meets the following conditions:
The union of sub-relations Y1 and Y2 should include all the attributes present in the original relation Y.
- The intersection of Y1 and Y2 should not be empty. A common attribute between Y1 and Y2 must exist, and this attribute should contain unique data. The common attribute must be a super key in either Y1 or Y2.
Example 1: Let's consider a relation named Numbers with columns A, B, and C:
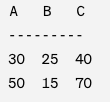
Now, we decompose this relation into two smaller relations, R1 and R2:
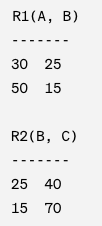
After performing the join operation on R1 and R2, we should get the original Numbers relation:
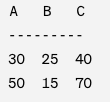
This demonstrates that the lossless decomposition preserves all the original data when dividing and rejoining the tables.
Example 2:
Let's consider:
Y=(M,N,O)
Y1=(M,N)
Y2=(N,Z)
In this example, the relation Y has attributes M,N, and O. After decomposition, we get two separate relations, Y1 and Y2, each with two attributes. The common attribute between Y1 and Y2 is N. It's important to note that the values in the N column must be unique. If there are duplicate values, a lossless-join decomposition would not be possible.
Example 3:
Consider a table with the relation X that contains the following raw data:
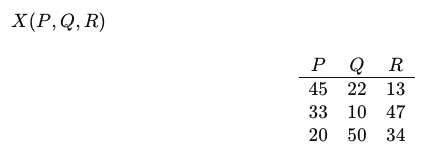
This relation can be decomposed into the following sub-relations, X1 and X2:

Let's check the first condition to determine if the decomposition is a lossless-join decomposition. In this case, the union of the sub-relations X1 and X2 should yield the same result as the original relation X.
X1∩X2=X
The resulting table is:

As the resulting table is identical to the original relation X, this decomposition can be considered a lossless join decomposition in DBMS.
Practice Question of lossless decomposition:
Consider a relational schema Y with attributes A,B,C, and D, and the following functional dependencies:
A→B,B→C,C→D,D→A
If the relation Y is decomposed into the following smaller relations:
R1(A,B),
R2(B,C),
R3(C,D)
The decomposition would:
A. Result in a lossless join but is not dependency preserving.
B. Result in a lossless join and is dependency preserving.
C. Not result in a lossless join and is not dependency preserving.
D. Not result in a lossless join but is dependency preserving.
Answer with Explanation: B. Result in a lossless join and is dependency preserving.
Explanation:
To determine if the decomposition is lossless and dependency preserving:
Lossless Join:
The intersection of the decomposed relations should include a super key of the original relation.
For R1 and R2, the intersection is B, and for R2 and R3, the intersection is C. Since both B and C are attributes that can derive other attributes, the intersection of all decomposed relations will give us all the attributes of Y.
Dependency Preservation:
All the functional dependencies in the original relation should be represented in the decomposed relations.
The given decomposition does represent all the functional dependencies from the original relation: R1 represents A→B R2 represents B→C R3 represents C→DFurthermore, the dependency D→A is indirectly preserved through the decomposition.
Therefore, the correct answer is B. Result in a lossless join and is dependency preserving.
Analyzing Lossy Decomposition
Lossy decomposition occurs when a single relation is divided into multiple relational schemas in a way that retrieving the original relation results in a loss of information. In other words, some data from the original relation may not be recoverable from the decomposed relations, leading to a loss of information.
Example:
Consider a relation X that is decomposed into n sub-relations: {X1,X2,X3,…,Xn}. If the natural join of these sub-relations does not yield the original relation X, it is classified as a lossy decomposition in DBMS.
Characteristics of Lossy Decomposition:
- Reduction in Data Redundancy: Lossy decomposition aims to reduce data redundancy by dividing a relation into smaller tables.
However, it may not retain all the original data, leading to potential data loss.
- Lack of Dependency Preservation:
Unlike lossless decomposition, lossy decomposition does not always maintain all the original functional dependencies in the smaller tables.
- Potential Data Loss:
Some data from the original relation may not be included or recoverable in the decomposed smaller tables.
- Lossy Decomposition in DBMS with Example
Careless decomposition, also known as lossy join decomposition, introduces extraneous tuples when performing the natural join of the sub-relations. These additional tuples can make it challenging to distinguish the original tuples from the decomposed relations.
Example 1:Let us consider the following table which has employee information:
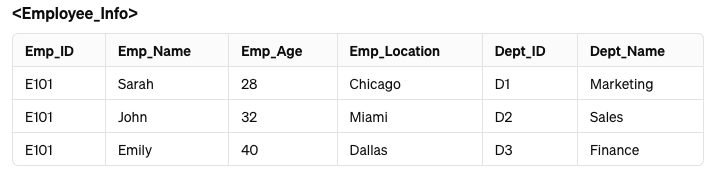
Now let us decompose this table into two sub tables:
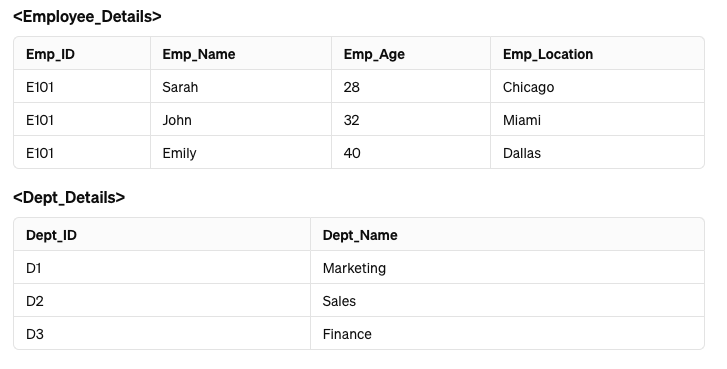
If we attempt to join both of the tables mentioned above, we won't be able to do so because the attribute Emp_ID is not included in the <Dept_Details> table.
Thus, this decomposition is an example of lossy decomposition.
Example 2:Let's consider the relation Y with attributes A,B,C.

Assuming this relation Y gets decomposed into Y1(A,C) and Y2(B,C) sub-relations, these two sub-relations would look like:

Let's check if this decomposition is lossy. For a lossy decomposition, we should have:
Y1⋈Y2⊇Y
Now, let's perform the natural join ⋈ of these sub-relations Y1 and Y2. The resulting table is:
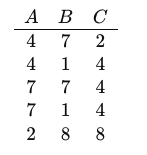
The resulting relation is not identical to the original relation Y and contains extraneous tuples.
Thus, Y1⋈Y2 ⊇Y.
In conclusion, the decomposition mentioned here is a lossy decomposition.
Practice Question of lossy decomposition:
- Check whether this decomposition given is a lossy join decomposition.
Consider a relation S with attributes X,Y,Z,W:
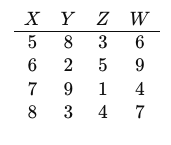
Assume that this relation S is decomposed into two sub-relations S1(X,Y,Z) and S2(Y,W) as follows:

Determine whether the decomposition is:
A. Lossless Decomposition
B. Lossy Decomposition
C. Cannot be determined
D. Both A and B
Answer with Explanation:
The decomposition is considered lossy if the natural join of the decomposed relations does not result in the original relation.
Now, let's perform the natural join ⋈ of S1 and S2:
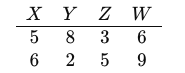
The resulting relation is not identical to the original relation S and contains only two rows, making this a lossy decomposition.
Thus, the correct answer is:
B. Lossy Decomposition
2. Check whether the given decomposition is a lossy join decomposition.
Original Relation:

Decomposition:

Is this decomposition:
A. Lossless Decomposition
B. Lossy Decomposition
C. Cannot be determined
D. Both A and B
Answer with Explanation:
Upon trying to join the two tables mentioned above, we won't be able to do it since the attribute ID is not present in the Location_Info table.
Thus, this relation mentioned here is a lossy decomposition.
Answer: Lossy Decomposition.
Summary and Key Concepts
Decomposition in DBMS
- Decomposition splits a table to remove duplicate data and enhance consistency.
What is Decomposition in DBMS?
- It divides a table into smaller tables for better organization.
- It must be lossless to ensure accurate data reconstruction.
Types of Decomposition
- Lossless Decomposition:
- Ensures the original table can be reconstructed accurately.
- Requires a common attribute in smaller tables.
- Lossy Decomposition:
- May result in the loss of some original data.
- Can introduce extra, unnecessary data.
Properties of Decomposition
- Enhances data organization and reduces redundancy.
- Lossless Decomposition Criteria:
- Union of decomposed tables should equal the original table.
- Dependency Preservation:
- Maintains all original functional dependencies.
Advantages of Decomposition in DBMS:
- Reduction of Data Redundancy: Decomposition removes repeated data by splitting the table into smaller ones.
- Improved Data Integrity: Organizing data better through decomposition makes the data more accurate and consistent.
- Facilitates Data Maintenance: It's easier to update or change data in smaller tables.
- Enhanced Query Performance: Decomposition can speed up database searches by reducing repeated data and improving table design.
- Flexibility in Database Design: Decomposition makes the database design more flexible, allowing easier changes and updates.
Disadvantages of Decomposition in DBMS:
- Loss of Information: In lossy decomposition, some original data can be lost.
- Complexity in Querying: Decomposition can make queries more complicated, especially when you need data from multiple tables.
- Dependency Maintenance: Managing connections between the smaller tables can be tricky, risking data mix-ups.
- Increase in Storage Overhead: More storage might be needed because of the extra tables and connections.
- Requires Expertise: Doing decomposition right needs a good understanding of database design and the specific needs of the database.
In summary, while decomposition has benefits like better data organization, it also has challenges that need careful handling to keep the database running smoothly.
Advanced Decomposition Techniques: BCNF and Fourth Normal Form (4NF)
When creating and refining a database, it's important to organize it properly to keep data accurate and avoid unnecessary repetition. To achieve this, we use advanced techniques known as Boyce-Codd Normal Form (BCNF) and Fourth Normal Form (4NF). Let's break down these concepts to make them easier to understand:
1. Boyce-Codd Normal Form (BCNF)
BCNF is a method to organize data in a database to minimize redundancy and maintain data consistency. The main rule for BCNF is that every piece of data (non-key attribute) in a table should only depend on the primary key.
Example:
Suppose we have a table called Student_Course:
Student_Course (Student_ID, Course_ID, Course_Name, Instructor)
To apply BCNF:
- Student_Course_Info:
Student_Course_Info (Student_ID, Course_ID)
- Course_Details:
Course_Details (Course_ID, Course_Name, Instructor)
Why is BCNF useful?
It ensures consistent data throughout the database and simplifies data updates without impacting various sections of the database.
2. Fourth Normal Form (4NF)
4NF builds upon BCNF by specifically targeting the elimination of multi-valued dependencies in the data; thus, a table in BCNF should be free of any multi-valued dependencies.
Example:
Consider the Employee_Project table:
Employee_Project (Employee_ID, Project_ID, Employee_Name, Project_Name)
In this table, Employee_Name is dependent on Project_ID, which is a multi-valued dependency.
To reach 4NF:
- Employee_Project_Info:
Employee_Project_Info (Employee_ID, Project_ID)
- Employee_Details:
Employee_Details (Employee_ID, Employee_Name)
- Project_Details:
Project_Details (Project_ID, Project_Name)
Why is 4NF useful?
It helps minimize data repetition by separating multi-valued attributes and ensures that the data remains accurate and free from anomalies.
Summary and Key Concepts
Advanced decomposition methods such as BCNF and 4NF are essential for efficient database structure. These techniques manage complex data structures and dependencies, improving data integrity, minimizing redundancy, and streamlining database maintenance.
Conclusion
Decomposition in DBMS is a crucial process that involves splitting down a single relation into multiple smaller relations to eliminate redundancy and improve data integrity.
There are two main types of decompositions:
- Lossless Decomposition:
Ensures we can rebuild the original table accurately from the smaller tables.
Requires a common attribute in the smaller tables.
- Lossy Decomposition:
May lose some original data when rebuilding the table.
Can create extra, unnecessary data.
Choosing between these types depends on the specific needs of the database. Proper use of decomposition is key for an efficient database design.
FAQs
1. What is non loss decomposition in DBMS?
Non-loss decomposition is a method in DBMS where the original table can be fully reconstructed from the smaller tables without losing any data.
2. What is redundancy in DBMS?
In DBMS, redundancy means having duplicate data in the database. This happens when the exact same information is stored in more than one place or table. Redundancy can happen due to reasons like inefficient database design or not following normalization principles.
3. What are the problems related to decomposition Explain?
Already mentioned under the heading disadvantage of decomposition in DBMS
4. What is decompose in SQL?
Decomposition in SQL means breaking down a single table into smaller tables to reduce redundancy and improve data organization.
5. What is decomposition and its type in DBMS?
Already mentioned under the heading What is decomposition and type in DBMS

Author|901 articles published





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
Disclaimer
The above statistics depend on various factors and individual results may vary. Past performance is no guarantee of future results.
The student assumes full responsibility for all expenses associated with visas, travel, & related costs. upGrad does not .