All courses
Agentic AI
Agentic AI

IIIT Bangalore
Executive Programme in Generative AI for LeadersArtificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership ProgrammeIIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, SwitzerlandGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsMBA
Masters

Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Executive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
Offline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)Paris School of Business
Master of Science in Business Management and Technology
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIIT-B & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
- uGSOT - B.Tech
More
%20(2)-db0b6f38da9c485faf76e366793c9b9e.webp&w=128&q=75)



8. BCNF in DBMS
16. Joins in DBMS
17. Indexing In DBMS
21. Deadlock in DBMS
29. B+ Tree
31. Database Schemas
Indexing In DBMS
Indexing is important in Database Management Systems (DBMS) as it provides the basis for efficient information retrieval. It minimizes the number of disk accesses required when processing queries; this streamlines the search process and significantly improves performance.
It is a primary database design concept that improves quick retrieval of records. Through effective indexing strategies, your database can become a well-organized repository that enables you to access your data quickly and comfortably.
In this guide, we will discuss indexing in DBMS in detail. We will also discuss its types and much more.
Overview
With indexing, records are arranged according to various attributes as a way of enhancing the retrieval process in databases. Each record in the DBMS is tagged with key information, making it a breeze to locate what you need swiftly.
Indexing is very useful when you're searching for a specific customer's details or a huge amount of data. Indexing in DBMS ensures that your database operations run smoothly and efficiently.
By the end of this guide, you will understand indexing in DBMS; I will discuss its types and importance with practical examples.
What Is Indexing In DBMS?
First, what is indexing? Indexing is essentially a method of organizing data in a database to make retrieval faster and more efficient. Think of it like a roadmap in a library: it helps you find books quicker by listing key topics or authors.
Indexing in DBMS involves constructing a roadmap for your data, making it easier to locate certain entries. Indexing in a database accelerates data retrieval by allowing the database engine to easily identify particular records using indexed columns. It simply makes the access to data smooth, speeds queries up, and ensures that information in databases remains accurate and consistent.
Indexing in DBMS is like a simplified table with two columns. The first column holds copies of unique identifiers from the main database table, while the second column contains pointers, indicating where each identifier's corresponding data is stored on the disk.
Real-World Applications Of Indexing In DBMS
Indexing in DBMS is used across industries in the world. Let’s discuss about its real-world applications.
1. E-Commerce Retail Store
Let's consider an example: Let's say you own an online retail store with thousands of products listed in your database. Without indexing, whenever a customer searches for a product, your system would need to scan through each record sequentially to find a match.
However, by implementing indexing on key attributes such as product names or categories, your DBMS can quickly pinpoint the relevant records, dramatically speeding up search queries. This means that when a customer searches for "smartphone," for instance, the system can efficiently retrieve all smartphone listings without having to sift through every product in the database.
2. In Healthcare
Indexing is equally important for managing patient records in the healthcare industry. Suppose you're a hospital administrator tasked with retrieving medical histories for patients. With indexing, you can expedite the process by organizing records based on patient IDs or medical conditions. This allows healthcare providers to access critical information promptly, enabling faster decision-making and improved patient care.
3. Financial Transactions
Indexing is also indispensable in financial systems where swift access to transactional data is paramount. For example, in a banking application, indexing customer account numbers or transaction dates ensures that banking operations such as balance inquiries or fund transfers are executed swiftly and accurately.
Types Of Indexing In DBMS
Indexing in DBMS is divided into different types. You should know about four types of indexing in a DBMS.
1. Ordered Indices
One common type of indexing is known as ordered indices. These indices are structured in a sorted manner, facilitating faster search operations.
Let's illustrate this with an example: Consider a large online retail database containing information about various products.
Product Code | Product Name | Price | Quantity Available |
ABC123 | Laptop | $899 | 50 |
DEF456 | Smartphone | $699 | 100 |
GHI789 | Smartwatch | $249 | 75 |
JKL012 | Headphones | $129 | 200 |
MNO345 | Tablet | $499 | 80 |
The table above includes columns for Product Code, Product Name, Price, and Quantity Available, with sample data filled in for each product.
Each product is uniquely identified by a product code, and you're searching for a specific product with code "ABC123". Without an index, the DBMS would need to scan through the entire database sequentially, which could be time-consuming, especially for large datasets.
However, with an ordered index based on product codes, the DBMS can efficiently locate the desired product. By referencing the index, the system can quickly navigate to the entry corresponding to product code "ABC123" and retrieve the associated product details, significantly reducing the search time.
2. Primary Index
Primary Indexing in DBMS further refines the indexing process in DBMS, offering two distinct types: dense index and sparse index.
(i) Dense Index
In a dense index, a record is created for every unique search key value in the database. This means that each distinct value has a corresponding entry in the index, pointing directly to the respective record on the disk.
For instance, consider a dense index implemented for customer IDs in an online retail database. Each unique customer ID would have its corresponding entry in the dense index, facilitating rapid retrieval of customer information based on their IDs.
Customer ID | Index Entry |
1001 | 1 |
1002 | 2 |
1003 | 3 |
1004 | 4 |
1005 | 5 |
In the table above, each row represents a unique customer ID along with its corresponding index entry in the dense index. This dense index structure facilitates rapid retrieval of customer information based on their IDs, enhancing database efficiency. Feel free to adjust the formatting and content within Microsoft Word as necessary.
(ii) Sparse Index
Sparse indexing provides a more optimized approach by creating index records only for select search-key values rather than for every value in the database. While this approach conserves space and reduces maintenance overhead, it may entail a slightly slower retrieval process compared to dense indexing.
For example, in a sparse index for product prices in the retail database, index records may be created only for specific price ranges rather than for every individual price point. This selective indexing strategy can still efficiently guide queries to relevant product entries while minimizing index overhead.
Price Range | Index Entry |
$0 - $99 | 1 |
$100 - $199 | 2 |
$200 - $299 | 3 |
$300 - $399 | 4 |
$400 - $499 | 5 |
In this example, the sparse index records are created for specific price ranges rather than for every individual price point. Each price range is paired with its corresponding index entry. This selective indexing strategy efficiently guides queries to relevant product entries while minimizing index overhead. Adjustments can be made to the formatting and content in Microsoft Word as needed.
3. Clustering Index
The clustering index is a key player for data organization in DBMS. Unlike traditional indices, cluster indexing in DBMS operates on ordered data files, offering a structured approach to data retrieval.
Consider a scenario where a company houses a multitude of employees across various departments.
Employee ID | Employee Name | Department ID |
1001 | John Smith | 101 |
1002 | Emily Johnson | 102 |
1003 | Michael Williams | 103 |
1004 | Jessica Brown | 101 |
1005 | David Jones | 104 |
Now, let's say we opt for a clustering index strategy. Instead of indexing based on a unique primary key, such as employee ID, we group employees based on shared characteristics, such as their department ID. This clustering enables us to create indexes for these cohesive groups, enhancing data retrieval efficiency.
Department ID | Cluster Index |
101 | 1 |
102 | 2 |
103 | 3 |
104 | 4 |
105 | 5 |
However, the conventional approach of sharing disk blocks among records from different clusters can introduce complexities. To mitigate this, a more refined technique involves allocating separate disk blocks for individual clusters, enhancing indexing efficiency further.
4. Secondary Index
Another important indexing technique in the realm of DBMS is the secondary index. Unlike primary indices, which typically operate on unique key fields, secondary indices leverage non-unique fields to generate indexes.
Let's discuss an example to illustrate secondary indexing in DBMS.
Let’s say a comprehensive bank account database is organized by account numbers. Now, suppose you need to retrieve all accounts belonging to a specific branch of ABC Bank.
Account Number | Account Holder Name | Account Type | Balance |
1001 | John Smith | Savings | $5,000.00 |
1002 | Emily Johnson | Checking | $3,200.00 |
1003 | Michael Williams | Savings | $7,500.00 |
1004 | Jessica Brown | Checking | $1,800.00 |
1005 | David Jones | Savings | $10,000.00 |
Herein lies how to use the secondary index in DBMS.
In this scenario, a secondary index is established for each search-key, providing a structured pathway to relevant data subsets. Each index record serves as a pointer to a bucket containing pointers to all records sharing the specific search-key value, facilitating efficient data retrieval.
Account Number | Secondary Index |
1001 | 1 |
1002 | 2 |
1003 | 3 |
1004 | 4 |
1005 | 5 |
In the table above, each row represents an account number along with its corresponding secondary index. This secondary index facilitates efficient data retrieval by providing a structured pathway to relevant data subsets, particularly when searching for accounts belonging to a specific branch of ABC Bank.
By employing a two-level indexing approach, secondary indexing minimizes the mapping size of the first level. This enhances data access even within large databases. This dynamic indexing strategy underscores the versatility and efficacy of secondary indices in enhancing DBMS performance.
Other Indexing Methods In DBMS
In DBMS, there are some other indexing methods that you should know about-
1. Multilevel Indexing
When conventional indexing approaches reach their limitations, multi-level indexing comes out as a solution in Database Management Systems (DBMS). The multi-level indexing in DBMS method comes into play when a primary index surpasses memory constraints, necessitating a more sophisticated approach to data organization.
Let’s say you manage a vast library catalog with millions of books. Each book entry contains various attributes such as title, author, publication year, and genre. Initially, you might have a primary index based on the ISBN (International Standard Book Number), allowing quick lookups of books by their unique identifiers.
However, as the library collection grows, the primary index becomes too large to fit entirely into memory. This poses a challenge because accessing data directly from a disk is slower compared to memory access. In such a scenario, multilevel indexing comes into play to optimize data retrieval.
Here's how multilevel indexing works in this library catalog example:
Organization into Sequential Files: Instead of having a single massive index, the book data is organized into sequential files on disk. These files could be categorized based on ranges of ISBNs, publication years, or other criteria.
Creation of Sparse Index: A sparse index is created based on these sequential files. This index contains information about which file or range of files contains the data corresponding to specific ISBNs or other search criteria.
Optimizing Disk Accesses: When a search query is made for a particular book, the system consults the sparse index to quickly identify the relevant file or range of files where the book's data is located. This significantly reduces the number of disk accesses required to retrieve the desired information, thus improving data retrieval performance.
Streamlining Data Retrieval: By streamlining data retrieval through multilevel indexing, the library catalog system can handle large volumes of data efficiently, even when memory constraints pose challenges. This ensures that library patrons can quickly access information about books they are interested in, leading to a better user experience overall.
2. B-Tree Index
The B-tree index is a top data structure for efficient data retrieval.
In a B-tree index, data is organized in a multilevel tree format, with each node representing a range of values. Notably, all leaf nodes of the B-tree contain actual data pointers, facilitating direct access to stored records. Furthermore, the interlinking of leaf nodes through linked lists enables the B-tree to support both random and sequential access patterns, catering to diverse querying requirements.
Key characteristics of B-tree indexing include:
- Leaf nodes typically contain between 2 and 4 values, optimizing storage efficiency.
- Paths from the root to leaf nodes maintain uniform length, ensuring balanced access across the tree structure.
- Non-leaf nodes, excluding the root, typically have between 3 and 5 children, maintaining tree balance and search efficiency.
Each node, except the root or leaf, maintains a balance between the number of children and the overall tree structure, ensuring optimal indexing performance.
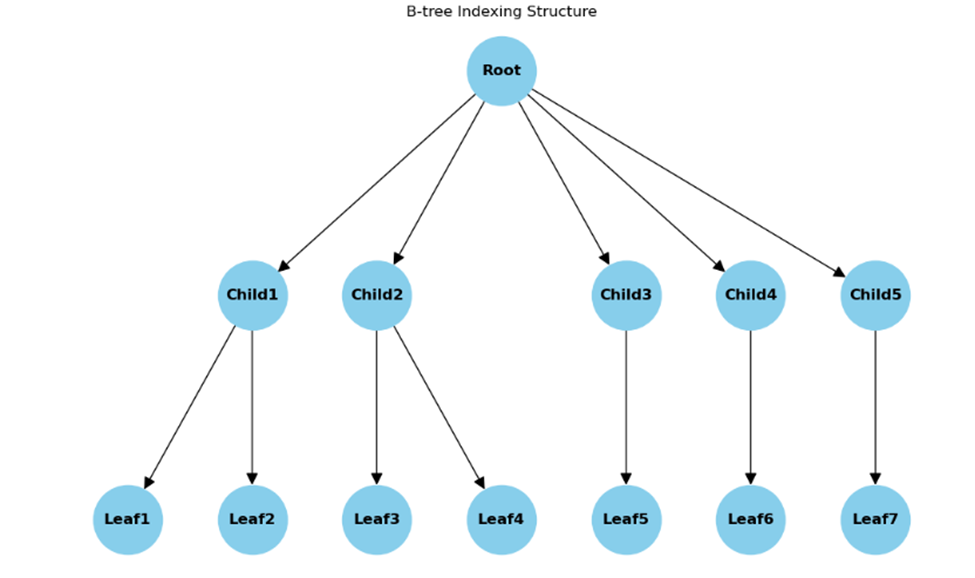
For example, if you run an online store, let's say you have a vast inventory of products stored in a database. Each product has a unique identifier, and customers often search for products based on various criteria such as product category, price range, or brand.
Here's how B-tree indexing enhances the efficiency of product searches:
Efficient Data Retrieval: The B-tree organizes product data in a hierarchical structure where each node represents a range of values. Leaf nodes contain actual data pointers, enabling direct access to product records. This means that when a customer searches for a specific product, the B-tree efficiently guides the system to the exact location of that product's information, minimizing search time.
Balanced Access Paths: Paths from the root of the B-tree to its leaf nodes maintain uniform length. This balanced structure ensures that no single path is significantly longer than others, leading to consistent and predictable performance regardless of the search criteria used.
Optimized Storage Efficiency: Leaf nodes typically contain between 2 and 4 values, optimizing storage efficiency by ensuring that each node stores a reasonable amount of data without overwhelming the system.
Support for Various Access Patterns: The B-tree supports both random and sequential access patterns. For instance, customers may search for products by entering specific keywords (random access) or browse through product categories (sequential access). The B-tree efficiently handles both types of queries, catering to diverse querying requirements without sacrificing performance.
Importance Of Indexing In DBMS
Optimization of database performance plays a significant role in indexing and enhancing overall efficiency. Let us now examine some key reasons why indexing is important:
1. Better Query Performance
Indexes make it easier for the database to retrieve information faster. This enables the database to find rows that match particular values or conditions through indexes created on columns often used in queries quickly, hence leading to a significant reduction in query execution time. For instance, well-designed indexes can make searches for specific customer IDs or product categories more efficient.
2. Efficient Data Access
Its minimal disk I/O requirements for retrieving information enable indexing to contribute to efficient data access. This implies that relevant pages with respect to specified criteria could be held within the memory, resulting in reduced disk read/write times during table scan operations, thereby making them faster.
3. Optimized Data Sorting
Indexing can also improve the performance of sorting operations within the database. By creating indexes on columns used for sorting, the database can avoid sorting the entire dataset and instead focus on sorting only the relevant rows. Sort processes are optimized within this optimization stream, more particularly in applications that require extensive data manipulation.
4. Uniform Data Performance
Indexing makes sure that the performance of a database remains consistent as the volume of data increases with time. Without indexing, executing queries takes longer when the dataset expands. However, with the proper implementation of indexes, a database can maintain a relatively even level of performance such that there is no change in response times for queries and transactions.
5. Data Integrity
Indexing facilitates data integrity by enforcing unique constraints on indexed columns. Indexing avoids insertion of duplicate values by imposing unique constraints on indexed columns thereby keeping the consistency and correctness of data at large. Queries and reports give credible results thus boosting overall data quality and usability.
6. Enhanced Concurrency Control
With indexing, one advantage is efficient concurrency control mechanisms within databases, too. By using indexes to direct traffic towards data access paths, databases are able to reduce contention while increasing throughput through multi-user environments like online transaction processing (OLTP) systems. This means that transactions process smoothly under heavy concurrent loads.
Conclusion
This absolute guide has covered various types of indexing such as ordered indices, primary indices (dense and sparse), clustering indices, secondary indices, multilevel indexing, and B-tree indexing.
Notably, by knowing how indexing works and utilizing appropriate techniques, your database can be made to run quite efficiently hence leading to business success.
FAQs
1. What is indexing DBMS?
Indexing in DBMS is a technique used to organize data in databases for faster retrieval. It creates a structured guide to the data, making it easier to locate specific records. Indexing in DBMS is a technique used to organize data in databases for faster retrieval. It creates a structured guide to the data, making it easier to locate specific records.
2. What is indexing, and explain its types?
Indexing is a method of organizing data in databases to improve retrieval speed. Types of indexing include ordered indices, primary indices (dense and sparse), clustering indices, secondary indices, multilevel indexing, and B-tree indexing.
3. What is the meaning of indexing?
Indexing refers to the process of organizing data in a database to make it easier and faster to retrieve specific information.
4. What are primary and secondary indexes in DBMS?
In DBMS, a primary index is based on the primary key of a table and ensures efficient retrieval of data. A secondary index, on the other hand, is created using non-primary key fields to further optimize data access.
5. What is indexing, and what type of indexing?
Indexing is the process of organizing data in a database to make retrieval faster. Different types of indexing methods are used, such as ordered indices, primary and secondary indices, clustering indices, and others.
6. Why is indexing important?
Indexing is important because it improves query performance, enhances data access efficiency, ensures consistent data performance, maintains data integrity, and facilitates efficient concurrency control in databases.
7. What is indexing in a database example?
An example of indexing in a database is creating an index on a customer ID field in a customer table. This index allows for quick retrieval of customer information based on their ID.
8. What is indexing and hashing in DBMS?
Indexing and hashing in DBMS are techniques used to optimize data retrieval. While indexing organizes data using a structured guide, hashing uses a hash function to map data to unique values for faster access.
9. What is indexing and partitioning in DBMS?
Indexing and partitioning in DBMS are methods used to improve data retrieval and management. Indexing organizes data for faster retrieval, while partitioning divides large tables into smaller, more manageable parts for efficient storage and access.

Author|899 articles published





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
Disclaimer
The above statistics depend on various factors and individual results may vary. Past performance is no guarantee of future results.
The student assumes full responsibility for all expenses associated with visas, travel, & related costs. upGrad does not .