Did you know? Before the introduction of the Collections Framework in JDK 1.2, Java's data structures like Vector and Hashtable lacked a unified architecture, making code maintenance difficult. Joshua Bloch developed the framework primarily to solve these issues and streamline data management in Java.
The collection framework in Java is a set of classes and interfaces that help you handle data efficiently. Whether you're storing objects in a list, set, or map, knowing how to use these structures is essential for effective coding. In this Java collection framework tutorial, you’ll explore the collection framework hierarchy in Java and understand how its interfaces are structured.
By the end, you'll clearly understand how to use Java collection to write cleaner, faster code.
What is Collection Framework in Java?
The collection framework in Java provides a set of classes and interfaces designed to manage groups of objects efficiently. It is a unified architecture that helps store and manipulate groups of objects.
Before JDK 1.2, Java used inconsistent collection classes. The introduction of the Collections Framework, led by Joshua Bloch, brought structure, scalability, and consistency to data handling.
Rather than creating your own custom solutions for storing data, Java provides this framework so you can focus more on the logic and functionality of your program. This makes your job as a developer much easier.
Purpose:
The main purpose of Java Collections is to streamline data handling through standardized operations and interfaces.
Think about it like this: When you need to work with a list of items (say, storing student names), you don't have to worry about the internal structure.
Java’s collections let you focus on performing actions like adding, removing, or searching for data, and it takes care of the rest behind the scenes. This is especially useful when dealing with large amounts of data or complex data structures.
Managing complex data structures can slow down your development process. Check out the Software Engineering Courses by upGrad, where you’ll learn to handle data with Java Collections and more efficiently. Start today!
Components of the Collection Framework
The Java collection framework is built around three key components that make data manipulation easier and more efficient: interfaces, implementations, and algorithms.
- Interfaces define the operations you can perform on collections, such as adding or removing elements. These interfaces provide a standardized way to interact with different collection types.
- Implementations (Classes) are the actual data structures that perform the operations defined by the interfaces. Classes like ArrayList, HashSet, and HashMap offer different ways to store and organize data based on your needs.
- Algorithms are built-in methods that handle common tasks such as sorting, searching, and manipulating data, saving you time and effort in writing custom code.
Each component in the collection hierarchy offers trade-offs in performance. For instance, ArrayList allows fast access by index, making it ideal for scalable read-heavy applications. On the other hand, HashSet ensures constant-time lookup, optimizing memory and performance when handling large, unique datasets.
Without the right skills, handling complex data tasks can be time-consuming. Enroll in the Masters in Data Science Degree by upGrad to master data management and accelerate your career in just 18 months. Start today!
Let’s explore the collection framework hierarchy in Java, where you’ll see how these components are related. Understanding the structure can make all the difference in your programming decisions.
Collection Framework Hierarchy in Java
The Java collection framework is structured to help you manage and manipulate data efficiently. At its core, it consists of interfaces defining the operations you can perform on collections.
Understanding the collection hierarchy helps developers choose the right data structure for specific needs. For example, if you need ordered elements with duplicates, List is preferred; but if uniqueness is required without duplicates, Set is the better choice.
Let’s break it down.
Understanding the Collection Framework Hierarchy
In the Java collection framework, the hierarchy defines how different types of collections are related to each other. Think of it like a family tree, where each collection type inherits traits from its parent interface.
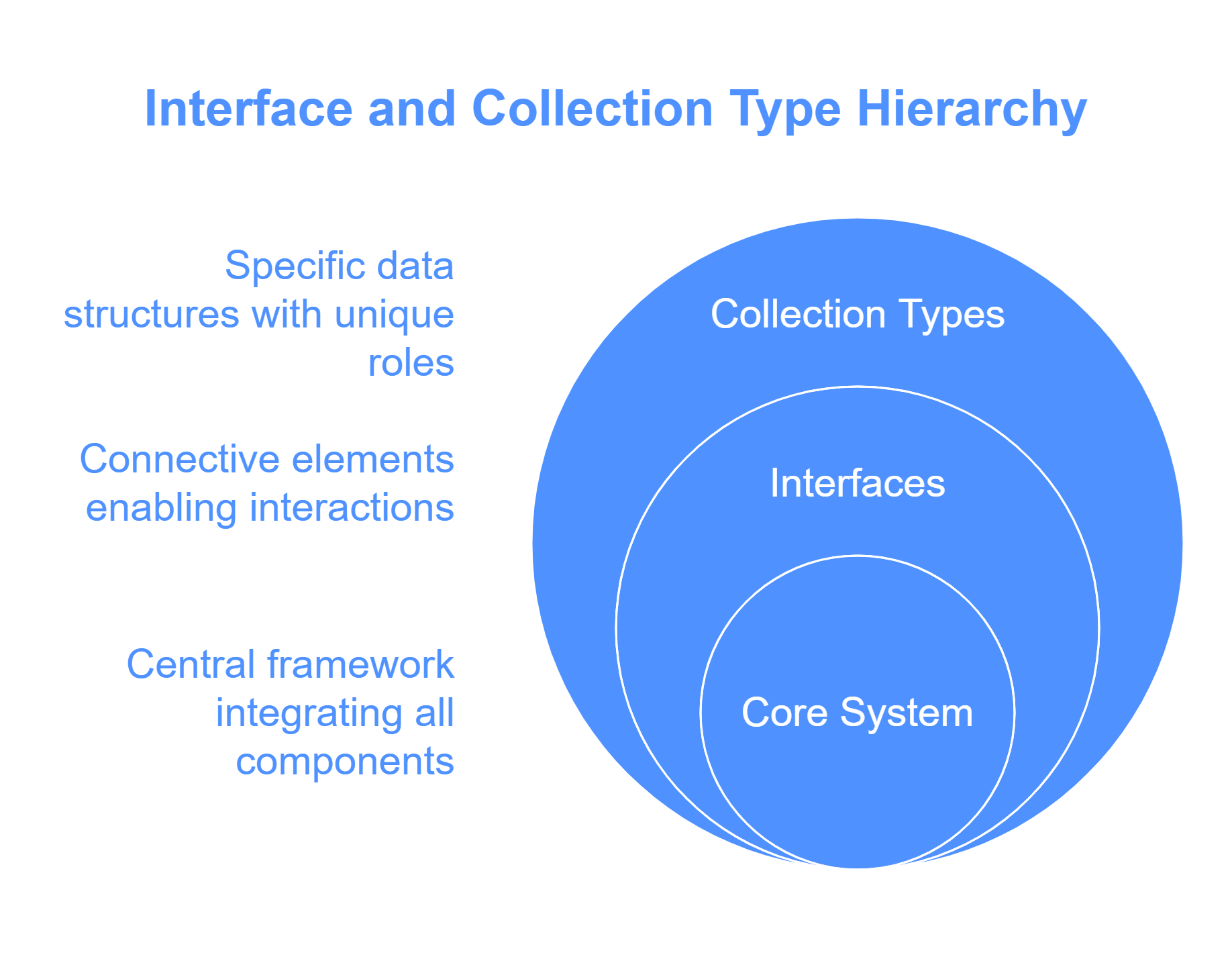
Understanding this hierarchy will give you clarity on how to approach different coding tasks.
- Core Interface: Collection
The Collection interface in Java is the root of the hierarchy. It defines basic operations, such as add(), remove(), size(), and contains(), which are common across all collection types. If you’re using any collection type, you’ll find these methods available.
- Why it matters: Knowing that all collections share these basic methods lets you work with them in a consistent way, no matter which specific implementation you choose.
The Collection interface has several subclasses that define specific types of collections with unique characteristics. These include:
- List: Stores elements in a specific order and allows duplicates.
- Set: Does not allow duplicate elements and is unordered.
- Queue: Typically used to store elements in a First-In-First-Out (FIFO) order.
- Map:While the Map interface doesn’t inherit from Collection, it is still part of the collection framework in Java.
A Map stores key-value pairs, each unique key, and its value can be any object. Unlike List or Set, Map stores entries as key-value pairs, making it ideal for fast lookup using unique keys. Even though it doesn’t inherit from Collection, it’s an essential part of the framework because it’s used frequently for tasks like storing configurations or user data.
Also Read: Collection vs Collections in Java: Difference Between Collection & Collections in Java
Let’s move forward and explore the key concepts of collections. You’ll dive into critical principles like generics and iterators and how these concepts make your code more flexible and efficient.
Key Concepts of Collections
To truly master the collection framework in Java, it's crucial to understand several key concepts that make collections both powerful and flexible. These include generics, iterators, and the characteristics of different collection types.
For example, using generics like List<String> helps ensure type safety by preventing unintended data types from being added.
List<String> names = new ArrayList<>();
names.add("Ajay");
Iterators allow safe traversal of collections and help avoid ConcurrentModificationException during iteration.
Iterator<String> it = names.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
Understanding these concepts will help you use collections effectively in Java.
Interfaces in Java Collections
In the collection framework in Java, interfaces define the operations that can be performed on collections. They act as blueprints, allowing various concrete classes to implement them.
Interfaces ensure that, regardless of the underlying implementation, all collections provide a consistent set of methods for adding, removing, and accessing elements.
Collection Interface
The Collection interface in Java is the root interface for all collections. It provides common operations that all collections must support.
- Methods:
- add(): Adds an element to the collection.
- remove(): Removes an element from the collection.
- contains(): Checks if the collection contains a specific element.
- size(): Returns the number of elements in the collection.
These methods allow basic operations on all collection types, ensuring uniformity.
List Interface
A List is an ordered collection that allows duplicate elements. This means that elements are stored in a specific sequence, and you can have multiple identical elements in a List.
- Methods:
- add(): Adds an element to the list.
- get(): Retrieves an element at a specified index.
- remove(): Removes an element from the list.
- Implementations:
- ArrayList: A dynamic array implementation of List. It offers fast random access and is ideal for lists that change in size frequently.
- LinkedList: A doubly linked list implementation that is efficient for insertions and deletions, but slower for random access.
Set Interface
A Set is an unordered collection that does not allow duplicate elements. This makes it ideal for ensuring uniqueness within a collection.
- Methods:
- add(): Adds an element to the set.
- remove(): Removes an element from the set.
- contains(): Checks if an element is present in the set.
- Implementations:
- HashSet: A set backed by a hash table. It offers fast lookups and doesn’t maintain any specific order of elements.
- TreeSet: A set that maintains elements in a sorted order, providing efficient lookup and retrieval, but at a slightly slower speed than HashSet.
Queue Interface
A Queue is a collection that stores elements in a First-In, First-Out (FIFO) order. It’s ideal for scenarios like task scheduling or handling requests in the order they arrive.
- Methods:
- offer(): Adds an element to the queue.
- poll(): Retrieves and removes the first element of the queue.
- peek(): Retrieves, but does not remove, the first element of the queue.
- Implementations:
- LinkedList: Can be used as a queue with fast insertion and removal of elements at both ends.
- PriorityQueue: Stores elements based on their priority, not in the order they were added. Elements with higher priority are dequeued first.
Map Interface
A Map is a collection that stores key-value pairs. Each key in a Map is unique, and the corresponding value can be accessed using its key. This makes Map ideal for use cases like storing configurations or user information.
- Methods:
- put(): Adds a key-value pair to the map.
- get(): Retrieves the value associated with a key.
- containsKey(): Checks if the map contains a specific key.
- remove(): Removes a key-value pair from the map.
- Implementations:
- HashMap: A map backed by a hash table. It provides fast access to keys and values but does not maintain any specific order.
- TreeMap: A map that maintains keys in a sorted order, which makes it slightly slower than HashMap but useful for applications where ordering is important.
- LinkedHashMap: A map that maintains the insertion order of keys.
Now that you understand the key interfaces and concepts, let's explore the classes in Java collections. These classes bring those interfaces to life and offer the practical tools you need to manage data in your applications.
Classes in Java Collections
These classes offer concrete implementations of the data structures, enabling you to store and manipulate data efficiently in Java applications. By understanding how each class works, you can choose the right one for your specific needs and improve your code’s performance.
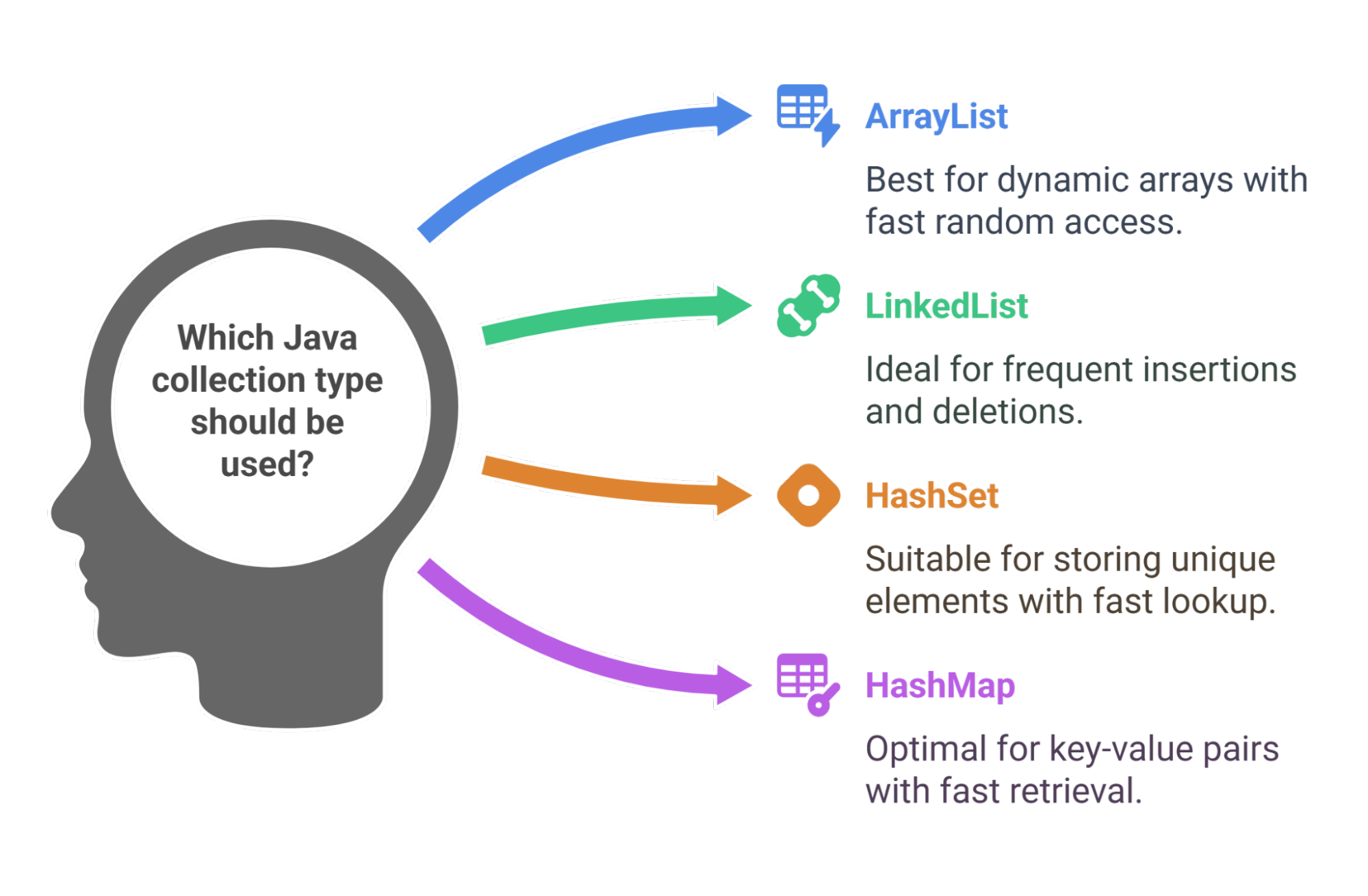
ArrayList
An ArrayList is a dynamic array implementation of the List interface. It automatically resizes itself as elements are added or removed.
- Characteristics:
- Allows duplicates: You can store multiple identical elements.
- Random access: You can access any element by its index quickly, making it ideal for situations where you need fast lookups.
- Resizable: Automatically resizes the array as you add elements, providing flexibility in dynamic data storage.
- Ordered: Maintains the order in which elements are inserted, allowing you to retrieve elements in the same sequence.
- Allows null values: You can add null as an element to the list.
- Efficient for sequential access: Great for iterating through the list from start to finish.
- Performance:
- Fast get() operation: Accessing an element at a specific index is efficient.
- Slower remove() operation: When you remove an element, the array may need to shift elements, which can make this operation slower.
- Example Use Case: Let’s say you have a list of students’ names in a class. Using an ArrayList allows you to quickly retrieve any student's name by their position in the list. However, if you need to remove a student from the middle, the list will have to shift the remaining students, which could be less efficient than other collections.
LinkedList
A linked list is a doubly linked list implementation of the List interface. It is composed of nodes, each containing an element and a reference to the next and previous nodes.
- Characteristics:
- Ideal for insertions and deletions: Because elements are linked, adding or removing items at the beginning or middle of the list is very efficient.
- Doubly linked: Each element is connected to both the next and previous elements, allowing easy traversal in both directions.
- Ordered: Maintains the order in which elements are inserted, similar to an ArrayList.
- Allows duplicates: You can store multiple identical elements.
- Allows null values: You can add null as an element to the list.
- Efficient for adding/removing at both ends: Ideal for stack and queue implementations, offering fast addFirst(), addLast(), removeFirst(), and removeLast() operations.
- Performance:
- Slower get() and set() operations: Accessing elements by index requires traversing the list sequentially, which can be slower than an ArrayList.
- Example Use Case:If you're building a to-do list application where tasks need to be frequently added or removed, a LinkedList is a great choice. It lets you easily insert or remove tasks from any position without shifting elements around.
HashSet
A HashSet is an implementation of the Set interface. It stores unique elements and doesn’t maintain any specific order.
- Characteristics:
- No duplicates: Ensures that every element in the set is unique.
- Uses hashing: This allows for fast lookups as elements are stored in a hash table, providing constant-time complexity for add(), remove(), and contains() operations.
- Unordered: Elements are not stored in any specific order, and the order of retrieval can vary.
- Allows null values: You can add null as an element to the set.
- Efficient for membership testing: Ideal for situations where you need to check if an element exists in the set without worrying about order.
- Fast performance: Due to hashing, operations like add(), remove(), and contains() are highly efficient.
- Performance:
- O(1) time complexity for add(), remove(), and contains() operations. This means these operations are executed in constant time on average, making HashSet a very efficient choice for checking membership.
- Example Use Case:Let’s say you must store a collection of unique email addresses for a newsletter. Using a HashSet ensures no duplicates, and checking if an email address is already in the set is quick.
TreeSet
A TreeSet is a sorted set that implements the Set interface. It maintains elements in natural order or according to a custom comparator.
- Characteristics:
- No duplicates: Just like HashSet, it does not allow duplicate elements.
- Sorted order: The elements are stored in a sorted order, either by their natural ordering or a custom comparator, ensuring they are always retrieved in a specific sequence.
- Uses a Red-Black tree: Implements a self-balancing binary search tree, allowing efficient operations.
- Allows null values: You can add null as an element, though only if the set uses a natural comparator that allows it.
- Slower than HashSet: Operations like add(), remove(), and contains() are slower than HashSet due to the overhead of maintaining the order.
- Efficient for range queries: Useful for retrieving a subset of elements in a specific range (e.g., from one value to another).
- Performance:
- Slower than HashSet: The TreeSet uses a tree structure (like a Red-Black Tree), which makes it slower than HashSet for basic operations, but the trade-off is that it guarantees elements will always be sorted.
- Example Use Case: If you're building a ranking system where you need to always display items in sorted order (e.g., top scores in a game), TreeSet is a good choice. It automatically keeps the elements sorted, saving you from needing to sort the list manually.
HashMap
A HashMap is an implementation of the Map interface that stores key-value pairs. It does not guarantee any specific order of the entries.
- Characteristics:
- Efficient lookups: Uses hashing to provide fast access to the value associated with a given key, offering O(1) time complexity for get(), put(), and remove() operations on average.
- No duplicate keys: Each key in the map must be unique. However, the values can be duplicated, meaning multiple keys can map to the same value.
- Unordered: The entries are not stored in any specific order, so the order of key-value pairs is not guaranteed.
- Allows null values and keys: You can add null as both a key and a value.
- Efficient for large datasets: Ideal for scenarios where you need quick lookups or need to store large amounts of data associated with unique keys.
- Performance:
- O(1) time complexity for put(), get(), and remove() operations, making it highly efficient for storing and retrieving key-value pairs.
- Example Use Case: If you’re building a phonebook application where you want to map each person's name to their phone number, a HashMap allows you to store and retrieve phone numbers using names as keys efficiently.
In Java, ArrayList offers fast random access and is ideal for scenarios with infrequent insertions and deletions, while LinkedList excels in frequent insertions and deletions but has slower access times.
HashSet ensures unique elements without maintaining order, whereas LinkedHashSet preserves insertion order.
For sorted elements, TreeSet is appropriate. In key-value pair mappings, HashMap provides quick lookups without order, LinkedHashMap maintains insertion order, and TreeMap keeps keys sorted.
Choosing the right collection class for your task can significantly impact your code’s performance and maintainability.
Also Read: Difference between Abstract Class and Interface
Now that you know how these collections work, let’s explore the benefits of Java collections and how they streamline your development process.
Benefits of Java Collections
The collection framework in Java brings several key advantages to your development process. It simplifies complex tasks, improves performance, and integrates seamlessly with other Java APIs, making it an essential tool for managing data in Java applications.
Let’s see how the collection framework enhances your programming experience.
Improved Code Efficiency
One of the primary benefits of using the collection framework in Java is that it reduces the complexity of your code. Instead of writing your own custom data structures from scratch, you can use built-in collections like ArrayList, HashSet, and HashMap.
Let’s say you're building a contact management system. Without the collection framework, you’d need to implement a custom data structure to store and search for contacts. With HashMap, you can store each contact's name as the key and their information as the value, saving you the effort of building a custom solution.
Flexibility in Data Management
Use ArrayList when you need an ordered list that allows duplicates, or use HashSet when you need unique elements.
Suppose you’re building a social media app. You could use an ArrayList to maintain an ordered feed of posts or a HashSet to store unique hashtags.
Simplified Data Structure Handling
The collection framework in Java provides standardized operations and interfaces, making it easy to work with complex data structures. You don’t need to manually implement methods like add(), remove(), or contains(), which are already available in the framework.
Imagine you’re managing a to-do list application. With the collection framework, you can use an ArrayList to store tasks and easily perform operations like adding a task, removing a task, or checking if a task exists, all with built-in methods.
Enhancements in Performance
The collection framework in Java provides access to highly optimized data structures. For example, HashMap uses a hash table to store key-value pairs, which allows for fast lookups with constant time complexity (O(1)) on average.
If you're building a recommendation system for an online store, using a HashMap to map user IDs to their past purchases will allow for quick retrieval of user data, making the system more responsive even with large datasets.
Integration with Java APIs
The Java collection framework integrates well with Java’s other APIs, such as Java 8+ features like Streams, forEach, and **Collectors`. This integration makes it easy to perform complex operations, like filtering, mapping, and reducing data, in a clean and readable way.
Suppose you're working on an application that processes customer orders. You can use Streams to filter orders by customer status (e.g., completed or pending) and then use collect() to group them by order date, all with simple and expressive code.
Thread Safety in Collections
When building multi-threaded applications, ensuring that your data structures are thread-safe is crucial. The Java collection framework provides thread-safe collections, such as ConcurrentHashMap and CopyOnWriteArrayList, that handle concurrent access from multiple threads.
ConcurrentHashMap is great for frequent reads and occasional writes, while CopyOnWriteArrayList is ideal when updates are rare, but reads are frequent.
Let’s say you're developing an online banking system where multiple users access their accounts simultaneously. Using a ConcurrentHashMap ensures that different threads can safely update and access customer data without causing data corruption or errors.
For read-heavy operations like accessing system-wide settings or user preferences, CopyOnWriteArrayList can be used to ensure thread safety without locking overhead.
Also Read: 50 Java Projects With Source Code in 2025: From Beginner to Advanced
Whether you're looking to streamline your code, boost performance, or integrate seamlessly with Java APIs, collections offer a robust solution for your programming needs.
Conclusion
In conclusion, understanding how to leverage the collection framework in Java is essential for efficiently managing and manipulating data in your applications. By familiarizing yourself with the different collection types, their operations, and performance considerations, you’ll improve your coding efficiency and problem-solving abilities.
Keep experimenting with various collections, apply them in your projects, and refine your skills to write cleaner, more efficient Java code. The more you practice, the more proficient you'll become in using Java collections to solve real-world problems.
If you want to deepen your understanding of PHP development or explore other areas in the tech field, upGrad’s career counseling services can guide you in choosing the right path. Visit your nearest upGrad center today for in-person guidance and take the next step in advancing your career!
FAQs
1. How do I choose the right collection for my Java project?
Choosing the right collection depends on your data handling needs. For example, use ArrayList for ordered data with fast random access, HashSet for unique elements with fast lookups, or HashMap from the map collection framework in Java for key-value pairs.
2. What’s the difference between the List and Set interfaces in Java collections?
The primary difference lies in order and duplicates. A List allows duplicates and maintains the order of elements, whereas a Set doesn’t allow duplicates and does not guarantee order.
3. When should I use HashMap vs TreeMap in the map collection framework in Java?
Use HashMap when you need fast lookups and don’t care about the order of the keys, as it offers constant-time complexity for operations. Opt for TreeMap when you need the keys to be sorted in natural order or a custom order, but be aware that it’s slower than HashMap.
4. Can I store null values in HashMap or TreeMap?
Yes, you can store null values in HashMap, and you can even use a null key in a HashMap. However, TreeMap doesn’t allow null keys because it relies on comparing keys, which can’t be done with null. Understanding Java Collection behavior with special values like null can help you avoid potential issues.
5. What is the best collection for frequent insertions and deletions in Java?
For frequent insertions and deletions, LinkedList is your best bet. It provides efficient operations for adding or removing elements from both ends or the middle of the list. Unlike ArrayList, which can be slow for insertions or deletions (due to resizing), LinkedList provides a more efficient solution for these operations.
6. How does HashSet handle collisions in Java collections?
HashSet uses a hash table to store elements. When two elements hash to the same value, it handles collisions by placing them in the same bucket and differentiating them using their equals() method. Knowing how HashSet works under the hood will help you leverage the collection framework in Java more effectively for unique data storage.
7. Can you explain how Iterator works with collections in Java?
An Iterator in Java provides a standard way to traverse through a collection without directly accessing the underlying data structure. It is particularly useful when you need to iterate over a List or Set. Using hasNext() and next() methods, it ensures safe iteration and eliminates the need for manual indexing, offering a clean way to handle data in your Java collections tutorial.
8. What is the Queue interface used for in Java collections?
The Queue interface in Java is used for handling data in a First-In-First-Out (FIFO) manner. It is ideal for situations like task scheduling, processing orders, or handling messages in a server. By using classes like LinkedList or PriorityQueue, you can manage queues efficiently, ensuring tasks are processed in the correct order, which is essential for multi-threaded applications.
9. How does Java Collections handle concurrency?
Java provides thread-safe collections like ConcurrentHashMap and CopyOnWriteArrayList that are designed to handle concurrent operations in multi-threaded environments. These collections ensure that multiple threads can safely modify and access data without causing inconsistencies.
10. What is the difference between HashSet and TreeSet?
The main difference is that HashSet is unordered and does not guarantee any particular order of elements, while TreeSet stores elements in a sorted order based on natural ordering or a comparator. TreeSet also performs slightly slower due to the tree structure it uses for sorting.
11. Can I use Map in the same way as List or Set in Java collections?
While Map is part of the collection framework in Java, it operates differently from List or Set. A Map stores data as key-value pairs, unlike List or Set, which store elements without key-value associations. You can use Map for cases where you need fast lookups by key, such as storing user profiles where the username is the key.
Take the Free Quiz on Java
Answer quick questions and assess your Java knowledge












-d9bdeff6165f4eb1ba2adcebde78e961.svg)







-ae8d039bbd2a41318308f8d26b52ac8f.svg)
-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)









-9cd0a42cab014b9e8d6d4c4ba3f27ab1.webp&w=3840&q=75)




