Introduction
Ever wondered how the code you write in a human-readable language like Python or Java is understood by a computer's processor? It's not magic, it's the work of a highly sophisticated translator called a compiler. But this translation isn't a single step; it's a multi-stage assembly line.
These stages are known as the Phases of a Compiler. Each phase has a specific job, from checking your code for errors to optimizing it for speed, before finally creating a program the machine can execute.
This tutorial will take you on a journey through all six Phases of a Compiler, breaking down this complex process into simple, understandable steps.
Want to master more real-world programming problems? Explore our Software Engineering Courses and boost your skills in programming with hands-on practice.
6 Phases of a Compiler
A compiler typically consists of six essential phases that work together to transform high-level source code into executable machine code. Each phase plays a crucial role in the overall compilation process. Let's explore each of these phases in detail:
i) Linear Analysis:
Linear analysis, also known as lexical analysis or scanning, is the first phase of a compiler. Its primary task is to scan the source code character by character and identify meaningful tokens. These tokens can include keywords (e.g., "if," "while," "int"), identifiers (variable or function names), operators (e.g., "+", "-", "*", "/"), constants (numeric or string values), and punctuation marks (e.g., brackets, commas, semicolons). Additionally, linear analysis eliminates extra whitespace and comments from the source code.
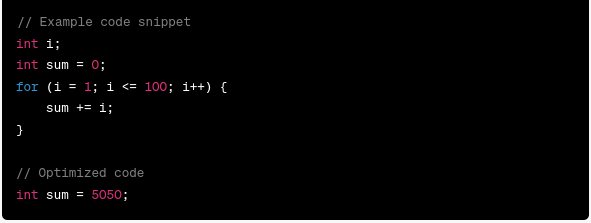
Consider, for example, the following C code fragment:

The linear analysis phase would identify tokens such as "int," "sum," "=", "0," "for," "int," "i," "=", "1," "<=", "10," "i++," "{," "sum," "+=," "i," ";," "}".
Output:
55
Want to dive deeper into how software works at its core? Strengthen your foundation in computer science and advance your career with our specialized learning programs in software development
ii) Hierarchical Analysis:
An abstract syntax tree (AST), also referred to as hierarchical analysis or parsing, is a tool for organizing the sequence of tokens produced by linear analysis into a hierarchical structure. The AST captures the source code's grammatical structure, including the relationships between tokens.
Using the preceding code example as an illustration, the hierarchical analysis phase would generate an AST representing the structure of the code. The AST would imply that "sum" is declared as a variable with an initialization expression of "0". In addition, it would signify the presence of a for loop with an initialization statement, a condition, an update statement, and the loop's code block.
The resulting AST for the specified code fragment would resemble the following:
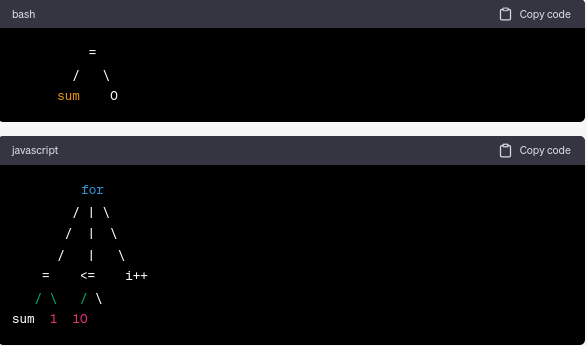
The AST's hierarchical structure serves as a basis for subsequent analysis and transformation.
iii) Semantic Analysis:
In the semantic analysis phase, the compiler verifies the semantic validity of the source code. It verifies type compatibility, enforces scope constraints, and eliminates ambiguities and inconsistencies. This phase guarantees that the code adheres to the language's rules and constraints.
For instance, consider the following code fragment:

A type mismatch would cause the compiler to detect an error during the semantic analysis phase. The first line declares and initializes "x" as an integer variable. The second line, however, attempts to designate a string value ("hello") to "x," which is incompatible. The semantic analysis phase would identify this discrepancy and report it as a type error.
Checking for undeclared variables, resolving variable scope conflicts, ensuring correct function usage, and performing other language-specific tests to ensure the code's meaning and integrity are also components of semantic analysis.
iv) Intermediate Code Generator:
The intermediate code generator is a phase of the compilation process that produces an intermediate representation of the code based on the output of the semantic analysis phase (typically an abstract syntax tree or other high-level representation). This intermediate representation functions as a bridge between the high-level source code and the executable machine code. It is designed to be platform-independent and facilitates code optimization and portability across multiple architectures.
The primary objective of the intermediate code generator is to generate an easily modifiable and optimizable simplified and structured representation of the code. It removes some of the complexities of the high-level code and focuses on expressing the program's essential operations and control flow. This intermediate code can take various forms, including three-address code, quadruples, and bytecode.
Throughout the generation of intermediate code, the compiler executes operations such as expression evaluation, control flow management, and memory management. It allocates temporary variables and labels, translates control structures (such as loops and conditionals), and generates instructions that represent the program's behavior, independent of the target architecture.
Let's consider an example to illustrate this process:

v) Code Optimization:
Code optimization improves the intermediate code generator's efficiency and performance. Optimization evaluates the intermediate representation and employs approaches to reduce execution time, memory utilization, and program efficiency.
Optimization methods include:
1. Constant Folding: Compiling constant expressions and replacing them with their outcomes. Reduces runtime computations.
2. Loop Optimization: Unrolling, fusing, or exchanging loops to improve efficiency. These optimizations reduce loop overhead and increase cache utilization.
3. Dead Code Elimination: Removing code that does not affect program output. Unreachable or unutilized code is included.
4. Register Allocation: Optimizing memory access and efficiency by assigning variables to CPU registers.
5. Inline Expansion: Replacing function calls with function code to eliminate call and return overhead.
6. Data Flow Analysis: Analyzing data flow through the program and identifying optimization opportunities based on variable usage and dependencies.
The target architecture and optimization methodologies heavily influence code optimization. Optimized code should maintain program semantics and perform well.
Here's an example to illustrate the power of code optimization:
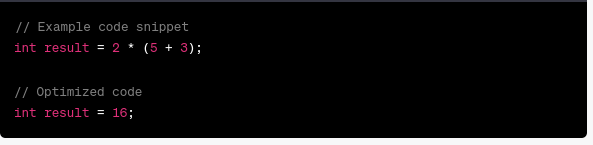
vi) Code Generation:
In the final phase of compilation, sometimes referred to as the synthesis phase of compiler, the compiler converts the optimized intermediate representation into executable machine code for the target architecture or platform.
The compiler selects instructions, allocates memory, and assigns registers during code generation. It converts the abstract program representation into hardware-executable instructions.
Code generation converts the intermediate representation into machine instructions that conduct the program's operations and control flow. The target architecture's instruction set, memory organization, and addressing modes determine these machine instructions.
The code generator uses earlier phase data to determine the most efficient machine code representation of the high-level program's behavior. It sets memory addresses for variables and data structures and generates code that interfaces with the target system's registers, memory, and I/O devices.
The code generation process converts the source code into executable code that can be loaded and run on the target platform.
Let’s look at the following example:

Code Optimizer
Together with the code generator, the code optimizer produces effective and optimized machine code. It uses techniques such as register allocation, loop unrolling, and instruction scheduling to improve the performance of the program. Consider the following example of code optimization:
Symbol Table
A symbol table is a data structure utilized by the compiler to store information regarding variables, functions, and other program entities. It provides a centralized repository for accessing and managing symbol-related data during the compilation's numerous phases. Symbol tables can be implemented using various data structures, such as lists, binary search trees (BST), and hash tables.
Symbol Table Management
Symbol table management involves creating, updating, and querying symbol tables during the compilation process. It ensures that all symbols are appropriately handled, their scopes are resolved, and their attributes are maintained accurately. The management of symbol tables directly influences the compiler's ability to analyze and generate code correctly.
Here's a simplified flowchart illustrating the basic steps involved in symbol table management within a compiler:
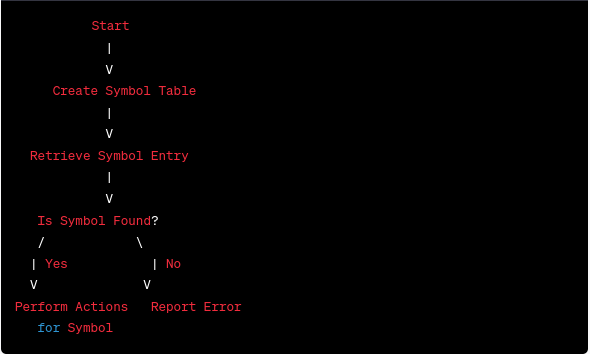
Dissecting the flowchart:
1. Start symbol table management.
2. Create Symbol Table: The symbol table is initialized to contain symbols found during compilation. It contains identifiers, variables, functions, constants, and their characteristics.
3. Retrieve Symbol Entry: When a symbol appears in code, the compiler attempts to retrieve its symbol table entry.
4. Is Symbol Found?: The compiler checks the symbol table entry.
- If yes, the compiler can type check, scope resolve, or generate code for the symbol.
- If No: Undefined symbol. The compiler errors because the symbol is undefined or out of scope.
5. Perform Symbol Actions: If the symbol is found, the compiler accesses its characteristics, does type inference, or generates code based on its usage.
6. Report Error: If the symbol is not in the symbol table, the compiler raises an error, indicating that it is undefined or undeclared.
This flowchart streamlines symbol table management for compilers. The complexity and implementation of the symbol table are dependent on the language and compiler design.
List
A list is a straightforward data structure that organizes its elements in a linear fashion. Lists can be used to represent symbol tables and other information pertinent to compiler design. They allow for straightforward traversal and sequential access to the stored elements.
Binary Search Tree
A binary search tree (BST) is a hierarchical data structure that makes searching, insertion, and deletion operations efficient. BSTs may be used to implement symbol tables in the context of a compiler. They provide quick symbol lookup and retrieval based on their keys.
Hash Table
Hash tables are data structures that expedite the retrieval of values based on the variables that are associated with them. By using a hash function to map keys to specified memory locations, hash tables are able to allow real-time access to the stored elements. Hash tables play a significant role In the implementation of symbol tables and other compiler-related operations.
Error Handling Routine
During the compilation process, the compiler may run into several errors, like mismatched types, syntax errors, or undeclared identifiers. Error handling routines are expected to detect and report these errors to the user. The crucial role that they play in providing meaningful error messages helps programmers debug their code effectively.
Run Time and Compile Time
The concepts of run time and compile time are fundamental in computer science and software development. Run time refers to the period during which a program is executed or runs on a computer system. It encompasses the actual
The terms "run time" and "compile time" pertain to different phases within the lifecycle of a program. The compilation process encompasses three main phases: source code analysis, transformation, and conversion to machine code. Runtime refers to the process of executing the code on the designated machine. The main purpose of a compiler is to enable a smooth transition from the compilation phase to the execution phase.
The Utilization of Compilers in Various Domains
Compilers find application in diverse domains, encompassing software development, system programming, and embedded systems. Programmers possess the ability to create code in high-level programming languages, which can subsequently be transformed into optimized machine code through the utilization of compilers. Compilers play a crucial role in enhancing program performance, improving developer productivity, and enabling the development of applications that can run on multiple platforms.
Conclusion
The journey from human-readable source code to an executable program is not a single leap but a methodical, multi-stage process. Understanding the Phases of a Compiler demystifies how this transformation happens, giving you a deeper appreciation for the tools you use every day.
This knowledge is more than just academic; it empowers you to write more efficient, optimized code by understanding how it will be analyzed and processed. A solid grasp of the Phases of a Compiler is a hallmark of a proficient software engineer who can think beyond the syntax and truly understand how their code performs.
FAQs
1. What is meant by the synthesis phase of a compiler?
The synthesis phase, or code generation, is the last phase of a compiler. It converts the optimized intermediate code into platform-specific machine code for the target platform.
2. Can you explain the structure of a compiler with examples?
Visualize the structure of a compiler as a pipeline, with each phase receiving input from the preceding phase and producing output for the subsequent phase. This sequential sequence guarantees the efficient transformation of source code into machine code.
3. What are the machine dependent phases of a compiler?
The target machine architecture or platform influences machine-dependent compiler steps. Code creation and target-specific optimization are included. Code generation converts optimal intermediate code into target machine-specific machine code. Target-specific optimization employs the target machine's qualities and characteristics to improve code performance and efficiency.











-d9bdeff6165f4eb1ba2adcebde78e961.svg)







-ae8d039bbd2a41318308f8d26b52ac8f.svg)
-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)














