Introduction
Think of Snowflake as a high-speed highway for your data, where information flows seamlessly, can be stored efficiently, and is ready for analysis anytime. In the fast-paced world of data management and analytics, mastering this cloud platform is essential.
This Snowflake Tutorial for Beginners guides you through the platform’s core concepts, features, and advantages. By the end of this Snowflake Tutorial, you’ll have a clear understanding of how to leverage Snowflake for efficient, cost-effective, and flexible data operations.
If you're looking to accelerate your data science journey, check out the Online Data Science Courses at upGrad. The programs help you learn Python, Machine Learning, AI, Tableau, SQL, and more from top-tier faculty. Enroll today!
The ease of use, dependability, and speed are important factors when picking a data platform because many firms struggle to make sense of all their data. Many firms now use cloud data platforms or plan to do so as part of a long-term strategic commitment to convert into a cloud-first, data-driven corporation.
Snowflake, the most popular choice, supports a variety of cloud infrastructures, including those from GCP, Microsoft, and Amazon. Thanks to its highly scalable cloud data warehouse, users can focus on data analysis rather than management and optimization.
Start your journey of career advancement in data science with upGrad’s top-ranked courses and get a chance to learn from industry-established mentors:
Let's examine Snowflake, one of the few enterprise-ready online data warehouses that provide simplicity without sacrificing capabilities.
What is a Snowflake Schema?
A variation of the star schema is the snowflake schema. The centralized fact table, in this instance, is linked to many dimensions. In the snowflake schema, dimensions are present in various connected tables in a normalized manner. The snowflake structure developed several layers of association and multiple parent tables for the kid tables. Only the dimension tables are impacted by the snowflake effect; the fact tables are unaffected.
A form of data modeling method called a snowflake schema is used in data warehousing to represent data in an organized way that is ideal for quickly querying massive amounts of data. A snowflake schema creates a hierarchical or "snowflake" structure by normalizing the dimension tables into numerous related tables.
The fact table is still in the middle of a snowflake schema, surrounded by the dimension tables. The resulting hierarchical structure resembles a snowflake since each dimension table is further divided into numerous related tables.
Example:
As an illustration, the product dimension table in a sales data warehouse may be normalized into several related tables, such as the product category, subcategory, and its details. Each of these tables would have a foreign key relationship with the product dimension table.
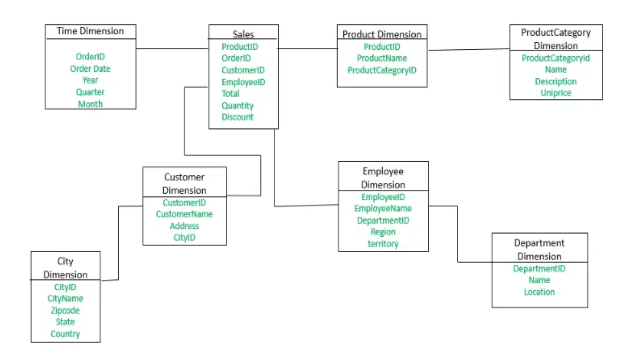
The following properties are now present in the Employee dimension table:
- EmployeeID
- EmployeeName
- DepartmentID
- Region
- Territory
The DepartmentID attribute connects the Department dimension table to the Employee table. The Department dimension is used to offer information about each department, including the agency's name and location. The following properties are now present in the Customer dimension table:
- CustomerID
- CustomerName
- Address
- CityID.
The Customer dimension table and the City dimension table are connected through the CityID attributes. Each city's name, Zip Code, State, and Country are listed in the City dimension table.
Now let’s create some beginner-level SQL codes for creating a Snowflake schema with the mentioned dimension tables:
- Department Dimension Table:
-- Create the Department dimension table
CREATE TABLE Department (
DepartmentID INT PRIMARY KEY,
DepartmentName VARCHAR(100),
Location VARCHAR(100)
);
- Employee Dimension Table:
-- Create the Employee dimension table
CREATE TABLE Employee (
EmployeeID INT PRIMARY KEY,
EmployeeName VARCHAR(100),
DepartmentID INT,
Region VARCHAR(50),
Territory VARCHAR(50),
FOREIGN KEY (DepartmentID) REFERENCES Department(DepartmentID)
);
Characteristics of Snowflake Schema
- Normalization: Snowflake schema follows the normalization process, minimizing data redundancy and ensuring data consistency.
- Star Schema Structure: Snowflake schema is a variation of the star schema, where dimension tables are further normalized into sub-dimension tables.
- Scalability: With Snowflake, you can effortlessly scale your data storage and computing resources as your data requirements grow.
- Ease of Maintenance: Due to its normalized structure, Snowflake schema requires less maintenance, making it easier to manage.
Also Read: Introduction to Cloud Computing: Concepts, Models, Characteristics & Benefits
Features of the Snowflake Schema
- Data Normalization
Data is arranged into numerous related tables in the snowflake schema, which is a normalized architecture. This increases data consistency and lowers data redundancy.
- Hierarchical Structure
The core fact table serves as the organization's hub in the snowflake schema's hierarchical structure. The metrics of interest are contained in the fact table, while the dimension tables provide the attributes that give the context of the metric.
- Multiple tiers
The snowflake schema allows for the existence of various tiers of dimension tables, each of which is connected to the main fact table. Users can then drill down into particular data subsets, allowing for a more detailed analysis of the data.
- Joins
The snowflake schema often necessitates more intricate SQL queries involving joins across numerous tables. This may affect performance, especially when working with huge data sets.
The Snowflake Architecture
Snowflake's architecture is built on three main layers:
- Cloud Services: This layer handles authentication, metadata management, and access controls. It ensures the security and governance of data.
- Query Processing: Here, SQL queries from users are processed, and the necessary computing resources are allocated dynamically.
- Database Storage: The storage layer stores data in a columnar format, optimizing query performance and reducing data storage costs.
Snowflake's architecture is designed to be a cloud-native, multi-cluster, and multi-tenant data warehouse solution. It separates compute resources from storage, allowing independent scaling of each component for optimal performance and cost-effectiveness. Below is an overview of the key components of the Snowflake architecture:
- Virtual Warehouse
The Virtual Warehouse (VW) is where data processing occurs. It is a compute resource that executes SQL queries and operations on the data stored in Snowflake. You can create multiple virtual warehouses with different sizes to handle various workloads and user concurrency. Scaling the virtual warehouses up or down can be done dynamically to match the demands of the workload.
- Compute Layer
The Compute Layer consists of multiple compute clusters managed by Snowflake. Each virtual warehouse has its dedicated computer cluster. These are automatically scaled up or down based on the workload and the number of concurrent queries.
- Storage Layer
The Storage Layer is responsible for persisting and managing data. Snowflake uses an object-based storage system provided by cloud service providers (AWS S3, Azure Blob Storage, or Google Cloud Storage). Data is stored in micro-partitions, which are immutable, compressed, and optimized for query performance. This separation of computing and storage enables efficient scaling and isolation of resources.
- Metadata Layer
The Metadata Layer contains all the information necessary to manage the data stored in Snowflake. It includes metadata about databases, tables, schemas, users, roles, and more. This metadata is stored in a highly optimized and distributed manner to ensure efficient access and management of the data.
- Query Processing
When a SQL query is issued, Snowflake's query optimizer breaks it down into smaller tasks and distributes them to the available compute clusters within the virtual warehouse. The data is read directly from the storage layer in parallel, and the results are aggregated and returned to the user. Snowflake optimizes query execution through techniques like pruning, filtering, and pushing down operations to minimize data movement.
- Multi-Tenancy
Snowflake is a multi-tenant system, meaning it securely serves multiple organizations or customers on the same infrastructure. Each company's data is logically isolated using databases and schemas. The metadata and access control mechanisms ensure that users from one organization cannot access data from another unless explicitly shared.
Also Read: DBMS Tutorial For Beginners: Everything You Need To Know
Advantages of Snowflake Schema
The Snowflake schema offers several advantages, making it a popular choice for organizing data in data warehousing environments. Some of them are:
- Reduced Data Redundancy: Snowflake schema stores dimension data in multiple related tables, reducing data redundancy and optimizing storage efficiency.
- Improved Data Integrity: The Snowflake schema enforces data integrity by normalizing dimension tables. Data anomalies, such as update anomalies, insertion anomalies, and deletion anomalies, are minimized since the data is stored in a structured and normalized manner. This ensures the accuracy and consistency of data.
- Easier Maintenance: The Snowflake schema makes data maintenance and updates easier. When changes are required in the dimension data, such as updating an attribute or adding new data, it only needs to be done in one place (the dimension table). This simplifies the data management process and reduces the chances of errors.
- Flexible Query Performance: Snowflake schema enables better query performance. Since dimension tables are normalized, smaller tables are created, and the database optimizer can efficiently handle complex queries, leading to faster query processing. The use of appropriate indexing further enhances query performance.
- Scalability: The Snowflake schema can handle large volumes of data efficiently. The normalized structure reduces storage requirements, making it easier to scale the database as data grows. Snowflake's architecture, which separates compute and storage, also allows for elastic scaling of compute resources to handle increasing workloads.
- Data Sharing and Integration: The Snowflake schema facilitates data sharing and integration. With normalized dimension tables, merging data from different sources and systems becomes easier. Snowflake's data-sharing capabilities allow seamless collaboration and sharing across different Snowflake accounts. Data can be shared as read-only or read-write, making it ideal for collaborative data analytics scenarios.
- Security: Snowflake schema enhances data security. Reduced data redundancy means fewer opportunities for unauthorized access to sensitive data. Additionally, Snowflake's robust security features, such as Role-based Access Control(RABC) and data encryption, ensure data is well-protected. It has external token authentication and multi-factor authentication for enhanced security.
- Schema Evolution: The Snowflake schema offers more flexibility in schema evolution. When there are changes in the data model, such as adding new attributes, it is easier to modify the normalized dimension tables without significantly affecting the overall schema structure.
Also Read: What is NoSQL Database: Growing Importance and Why They Matter for Your Career!
Disadvantages of Snowflake Schema
- Complexity: Although Snowflake is user-friendly, its advanced features may require a learning curve for some users.
- Cost: While Snowflake offers a pay-as-you-go model, storing and processing large volumes of data can result in higher costs.
Conclusion
Snowflake has transformed data management and analytics with its cloud-based architecture, scalability, and seamless integration. This Snowflake Tutorial for Beginners will help you understand the Snowflake schema, architecture, and key features, enabling you to harness its power for data-driven insights and smarter business decisions. Dive in and explore how Snowflake makes managing and analyzing data efficient and cost-effective.
FAQs
1. How does Snowflake handle data backups and disaster recovery?
Snowflake automatically handles data backups and provides continuous data protection. Backups are stored redundantly in different availability zones, ensuring data resilience and enabling point-in-time recovery in case of any failures or disasters.
2. How does Snowflake handle concurrency and performance in data processing?
Snowflake's architecture is designed to handle high concurrency and optimize performance. Each virtual warehouse (compute cluster) can be scaled dynamically based on the number of concurrent users and queries. Snowflake's query optimizer breaks down queries into smaller tasks and distributes them across the available compute clusters, allowing parallel processing and efficient utilization of resources.
3. How does Snowflake handle data loading and unloading efficiently?
Snowflake's architecture is designed for seamless data loading and unloading. To load data into Snowflake, users can use various methods such as bulk loading, bulk copy, or Snowpipe, which is its continuous data ingestion service. Snowpipe automatically loads new data as it arrives in the cloud storage, ensuring real-time data availability for processing and analytics. Snowflake's data loading process is optimized for parallelism and can handle large-scale data ingestion with ease. On the other hand, for data unloading, Snowflake provides various export options like sending to cloud storage, S3, or Azure Blob storage, making it convenient to export data for further analysis or archival purposes.











-d9bdeff6165f4eb1ba2adcebde78e961.svg)







-ae8d039bbd2a41318308f8d26b52ac8f.svg)
-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)














