All courses
Agentic AI
Agentic AI

IIIT Bangalore
Executive Programme in Generative AI for LeadersArtificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership ProgrammeIIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, SwitzerlandGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsMBA
Masters

Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Executive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
Offline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)Paris School of Business
Master of Science in Business Management and Technology
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIIT-B & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
- uGSOT - B.Tech
More



1. SQL Tutorial
3. SQL Commands
5. SQL Aliases
10. SQL WHERE Clause
11. SQL AND Operator
13. SQL Like
16. MySQL Workbench
22. Index in SQL
24. Schema in SQL
31. SQL ORDER BY
38. NVL in SQL
41. SQL Wildcards
45. GROUP BY in SQL
46. SQL HAVING
47. EXISTS in SQL
48. SQL Joins
53. Self Join SQL
54. Left Join in SQL
57. Cursor in SQL
58. Triggers In SQL
61. REPLACE in SQL
63. Transact-SQL
64. INSTR in SQL
70. Advanced SQL
71. SQL Subquery
78. MySQL database
79. What is SQLite
80. SQLite
Mastering Data Aggregation with GROUP BY in SQL
Introduction
Imagine you're running an enterprise and have mountains of sales data. Sifting through individual transactions would not be very insightful. This is where data aggregation is available in – it is like summarizing your data into helpful buckets for less complicated evaluation.
Data aggregation in SQL entails combining rows with comparable functions and calculating summary data for each group. Think of it like sorting a bag of mixed candies by using color. Instead of looking at every candy in my view, you could quickly see how many red, green, and blue sweets you've got.
The GROUP BY clause is your secret weapon for information aggregation in SQL. It acts like a sorting tool, grouping rows that percentage the same values in one or more columns. Let's say you need to research sales figures via product category. GROUP BY in SQL will categorize all your sales transactions primarily based on the product category, allowing you to calculate general sales, average order fee, or every other applicable statistic for every category.
By using GROUP BY in SQL with the product category and studying sales data, you may uncover precious insights. For instance, you may see which categories are top sellers, pick out any seasonal trends, or spot products with low sales figures that might want advertising efforts.
This is just a glimpse into the strength of GROUP BY in SQL. In the subsequent sections, we're going to delve deeper into its functionality, discover diverse combination functions you may use with it, and exhibit how to address extra complex data evaluation eventualities. So, buckle up and get equipped to master the artwork of data aggregation with GROUP BY in SQL with examples!
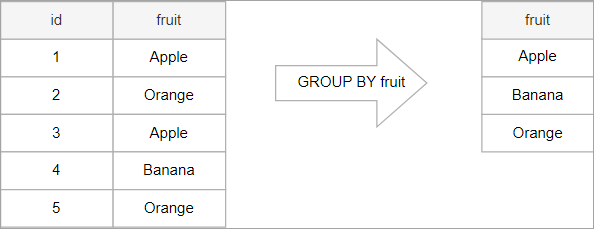
Understanding the GROUP BY Clause
The GROUP BY clause is an effective SQL device that permits you to summarize data based on shared functions. It's like sorting a pile of socks by shade – you emerge with groups of socks with identical colors, making it simpler to matter or examine them.
Syntax:
The basic syntax for the GROUP BY clause is as follows:
SQL
SELECT column_name(s), aggregate_function(column_name)
FROM table_name
GROUP BY column_name(s);
Explanation:
- SELECT: This keyword specifies the columns you want to retrieve from the table.
- Column_name(s): These represent the columns you want to institution the data via. You can specify one or more columns right here.
- Aggregate_function: This refers to a function used to summarize the data within each group (e.g., COUNT, SUM, AVG, and so on.). We'll discover these functions in the element later.
- FROM: This keyword shows the table containing the data you need to paint with.
- GROUP BY: This keyword introduces the grouping operation.
- Table_name: This is the call of the table you're querying data from.
Grouping Rows by Shared Values
Imagine you have a customer table with data like customer ID, city, and buy amount. You might need to recognize how many customers live in every city. This is in which GROUP BY in SQL comes.
SQL
SELECT city, COUNT(*) AS total_customers
FROM customers
GROUP BY city;
This query groups the rows inside the customer's table by using the city column. The COUNT(*) function then counts the wide variety of rows in each organization, basically telling you how many customers reside in every city.
Aggregate Functions for Summarized Insights
GROUP BY in SQL is often used alongside a mixture of capabilities that summarize data within every organization. Here are some common aggregate functions:
- COUNT(*): Counts the wide variety of rows in every group.
- SUM(column_name): Calculates the full cost of a numeric column inside each institution.
- AVG(column_name): Calculates the common price of a numeric column within every group.
- MIN(column_name): Identifies the minimal cost of a column within each institution.
- MAX(column_name): Identifies the maximum cost of a column within each institution.
By combining GROUP BY in SQL with aggregate functions, you may extract valuable insights out of your data. It's like taking a jumbled series of data and transforming it right into a clear and organized summary.
Common Aggregate Functions with GROUP BY
Having explored the fundamentals of the GROUP BY clause, permit's delve into the arena of combination features! These powerful companions paint hand-in-hand with GROUP BY in SQL to summarize data within every institution, offering treasured insights from your database tables.
The COUNT function tallies the wide variety of rows inside each organization. It's the workhorse for expertise how much information fall into every category described by way of your GROUP BY clause.
There are two major methods to install COUNT:
1. COUNT(*)
The asterisk (*) acts as a wildcard, signifying that we need to count all rows in every institution, irrespective of any unique column cost.
Imagine we have a table tracking customer orders. By the use of the following query:
SQL
SELECT Country, COUNT(*) AS TotalOrders
FROM CustomerOrders
GROUP BY Country;
We can retrieve the total number of orders located by customers from each country. The result may appear to be. This lets in us to pick out our purchaser base's geographical unfold and doubtlessly goal advertising efforts as a result.
2. COUNT(column_name)
Here, we specify a particular column call inside the parentheses. COUNT will then tally only the rows wherein that unique column has a fee, not null entries.
For example, if we want to know the number of lively customers (people with at least one order), we will use:
SQL
SELECT Country, COUNT(CustomerID) AS ActiveCustomers
FROM CustomerOrders
GROUP BY Country;
This query considers only rows in which the CustomerID has a fee, supplying a correct image of our active customer base with the aid of the US.
Unveiling Total Values with SUM
The SUM function calculates the overall number of walks for a numeric column inside every institution. It's instrumental for expertise in the cumulative price related to every category described by GROUP BY in SQL.
For example, considering the CustomerOrders table once more, we will employ SUM to investigate our overall sales performance:
SQL
SELECT ProductCategory, SUM(OrderAmount) AS TotalSales
FROM CustomerOrders
GROUP BY ProductCategory;
This query calculates the whole sales amount for each product category. This data is critical for product performance analysis and strategic inventory management.
Note: SUM only works with numeric data types like integers or decimals.
Averaging Out: Unveiling Central Tendencies with AVG
The AVG function computes the average cost of a numeric column within every group. It enables us to recognize the everyday price within a selected category.
Continuing with the CustomerOrders table, we are able to leverage AVG to research common order values:
SQL
SELECT Country, AVG(OrderAmount) AS AverageOrderValue
FROM CustomerOrders
GROUP BY Country;
This query calculates the common quantity spent consistent with the order in every state of the US. This expertise can aid in tailoring our advertising and marketing techniques based totally on purchaser spending behavior in exceptional areas.
Note: AVG is prone to outliers. A single very excessive or low price can skew the average. Be conscious of potential outliers when interpreting the results.
Advanced GROUP BY Techniques
Mastering the GROUP BY clause unlocks an effective level of data analysis in SQL. We've explored the fundamental functionalities, but there is extra to this clause that meets the attention. Let's delve into advanced techniques so as to refine your information manipulation competencies.
Filtering Groups with the HAVING Clause
The GROUP BY clause agencies rows, but what if you handiest need unique organizations based on the aggregation results? Enter the HAVING clause. It acts like a filter out after the grouping is completed, permitting you to pick organizations that meet certain conditions.
Example: Identifying Top-Selling Product Categories
Imagine you have a sales table and want to discover product categories exceeding a particular sales target of $10,000. Here's how HAVING works:
SQL
SELECT category, SUM(sales_amount) AS total_sales
FROM sales_data
GROUP BY category
HAVING SUM(sales_amount) > 10000;
This query groups sales data via category (the use of GROUP BY category), calculates the whole sales for each category (using SUM(sales_amount) AS total_sales), and then filters the groups with the use of the HAVING clause. The HAVING situation checks if SUM(sales_amount) is extra than 10,000, ensuring best categories exceeding the goal are covered in the outcomes.
Experimenting with Different Aggregate Functions
The HAVING clause works with diverse combination features, no longer just SUM. Here are a few examples:
- HAVING COUNT(*) > 10: Filter agencies with more than 10 rows (beneficial for identifying categories with a high number of merchandise).
- HAVING AVG(cut price) > 0.1: Filter organizations where the common bargain is more than 10% (useful for studying promotional effectiveness).
- HAVING MIN(stock_level) < 5: Filter agencies in which the minimum inventory stage is beneath 5 (useful for stock management).
The HAVING clause empowers you to refine your evaluation by summarizing options inside your grouped data.
SQL GROUP BY Multiple Columns for Granular Analysis
The GROUP BY clause isn't always restricted to single columns. You can organize information based totally on multiple columns for even extra granular evaluation. This is like developing a multi-layered hierarchy within your information.
Example: Analyzing Sales with the Aid of Product Category and Year
Let's say you want to analyze sales performance now not simply by product category but additionally by way of year. Here's how to obtain this:
SQL
SELECT category, year, SUM(sales_amount) AS total_sales
FROM sales_data
GROUP BY category, year;
This query groups the sales data by each category and year the usage of a comma-separated listing inside the GROUP BY clause. This creates a two-dimensional grouping, permitting you to look how sales for each category range throughout exceptional years.
Rollup and Cube: Advanced Grouping Extensions (For Eager Learners)
The world of GROUP BY in SQL extends past what we've got included up to now. ROLLUP and CUBE are advanced extensions designed for hierarchical data aggregation. They allow you to create multi-level summaries of your data. However, they contain greater complicated ideas.
These are advanced concepts, so focus on mastering the core functionalities of GROUP BY in SQL and HAVING before diving into ROLLUP and CUBE.
By incorporating HAVING, grouping by a couple of columns, and exploring advanced extensions, you've accelerated your SQL skillset for data manipulation. Remember, practice is prime. Experiment with different datasets and situations to solidify your know-how of those effective GROUP BY techniques.
Real-World Example: Website Traffic Analysis
Let's delve into a sensible example to illustrate the power of GROUP BY in movement. Imagine you are an internet site administrator and want to understand how users are finding your website. You have a table named website_traffic containing data like source (wherein the user got here from), landing page (the page they first considered), and go to count (variety of visits from that supply).
Sample Dataset:
Source | Landing Page | Visit Count |
Search Engine | /blog/seo-tips | 1254 |
Social Media | /product/widget | 789 |
Email Marketing | /about-us | 423 |
Direct Traffic | /home | 2310 |
Understanding User Acquisition with COUNT
A simple evaluation includes counting visits from every source. Here's a SQL query with the usage of GROUP BY in SQL and COUNT(*) to achieve this:
SQL
SELECT source, COUNT(*) AS total_visits
FROM website_traffic
GROUP BY source;
Output:
Source | Total Visits |
Search Engine | 1254 |
Social Media | 789 |
Email Marketing | 423 |
Direct Traffic | 2310 |
This result provides a short evaluation of user acquisition channels. Search engine site visitors seem to be the best, accompanied by direct visitors.
Average Visit Count in Line with Source with AVG
What if you need to recognize how users from every source interact with your website online? We can calculate the common visit remembered per source using GROUP BY and AVG(visit_count):
SQL
SELECT source, AVG(visit_count) AS avg_visits_per_source
FROM website_traffic
GROUP BY source;
Output:
Source | Avg Visits per Source |
Search Engine | 1.254 |
Social Media | 0.789 |
Email Marketing | 0.423 |
Direct Traffic | 2.310 |
This evaluation shows that users from direct site visitors generally tend to visit more pages in comparison to the ones arriving via social media.
Additional Use Cases of GROUP BY
Here are a few other precious programs of GROUP BY across various domains:
Sales Analysis:
- Group sales data by product category or vicinity to become aware of top-promoting gadgets and target unique markets.
- Calculate average order cost and general sales for extraordinary sales channels.
Customer Segmentation:
- Group customers with the aid of demographics or buy history to create centered advertising campaigns.
- Identify consumer segments with excessive lifetime value and tailor loyalty applications.
Inventory Management:
- Group stock data by product or location to track stock ranges and save you stockouts.
- Analyze product sales tendencies with the use of GROUP BY to optimize inventory management.
Human Resources:
- Group employee information by using department or position to research profits developments and become aware of capability pay gaps.
- Calculate common employee tenure for exclusive departments.
By learning GROUP BY and its associate mixture functions, you could liberate a wealth of insights hidden inside your data. It empowers you to make data-pushed selections and acquire better effects in any discipline.
Ready to Dive Deeper? Practice Makes Perfect!
We've explored the thrilling international of information aggregation in SQL, in particular focusing on the GROUP BY clause. By now, you need a group to know how GROUP BY in SQL empowers you to arrange your data into meaningful categories and unleash precious insights through mixture capabilities.
Now that you're equipped with the information of GROUP BY in SQL, it's time to test! Grab a few sample datasets or use your current data to begin crafting your personal SQL queries. Play around with extraordinary combination capabilities and notice how they manage your grouped data. The greater you practice, the more cushty you will emerge as in wielding the energy of GROUP BY in SQL for insightful data evaluation.
Remember, this is simply the start of your SQL journey. As you discover, you will come across even more advanced functionalities like HAVING clauses for filtering groups and GROUP BY in SQL with multiple columns for even extra granular analysis. But for now, focus on gaining knowledge of the core concepts we have covered, and you'll be nicely on your way to unlocking the secrets and techniques hidden within your data.
FAQs
1. What is the function of GROUP BY HAVING in SQL?
`GROUP BY` is a clause in SQL that is used to combine rows that have similar values into summary rows. `HAVING` is used in combination with `GROUP BY` to filter grouped rows based on some specified conditions. It makes it possible to sort data using the aggregation function.
2. What is GROUP BY and ORDER BY in SQL?
`GROUP BY` is used to have rows that have the same values to be grouped into summary rows where aggregate functions like `COUNT,` `SUM,` `AVG,` etc., are performed on each group. `ORDER BY,` unlike the other one, is employed to arrange the output in either ascending (default) or descending order by providing the columns or expressions.
3. What is the difference between GROUP BY and HAVING?
`GROUP BY` is used to group rows with the same values into summary rows, whereas `HAVING` is used to filter the grouped rows based on the specified conditions. `GROUP BY` is run before the aggregation, while `HAVING` is run after the aggregation. 4. Which comes first, GROUP BY or ORDER BY. In SQL query, `GROUP BY` is usually before `ORDER BY`. First, rows are grouped according to the columns or expression specified in the `GROUP BY` statement, and then the results are sorted using the columns or expression specified in the `ORDER BY` statement.
4. Which is faster, WHERE or HAVING?
In general, `WHERE` is more effective than `HAVING.` The reason lies in the fact that `WHERE` filters the rows before any grouping or aggregation is performed, which in turn reduces the number of rows that need to be processed. Contrarily, `HAVING` filters the result set after the grouping and aggregation has already been performed, which can lead to more overhead.
5. Why should we use GROUP BY?
GROUP BY is a function used to perform aggregation on groups of rows with similar values. It does the aggregation of data, calculating counts, sums, averages, etc., and gets insights into the dataset by analyzing the grouped data.
6. Do we have the privilege to use GROUP BY after ORDER BY?
No, the standard syntax of SQL requires the specification of GROUP BY before ORDER BY. The result set is first grouped by the columns or expressions contained in the GROUP BY clause, and then the dataset is sorted by the columns or expressions in the ORDER BY clause.
7. Is GROUP BY used before WHERE?
Yes, the typical SQL query typically has the following logical order of processing: WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY. This implies that initial filtering with WHERE happens before grouping with GROUP BY in SQL. The WHERE clause filters rows before any grouping takes place.

Author|309 articles published





upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
Disclaimer
The above statistics depend on various factors and individual results may vary. Past performance is no guarantee of future results.
The student assumes full responsibility for all expenses associated with visas, travel, & related costs. upGrad does not .