All courses
Agentic AI
Agentic AI

IIIT Bangalore
Executive Programme in Generative AI for LeadersArtificial Intelligence
Degree / Exec. PG

IIIT Bangalore
Executive Diploma in Machine Learning and AI
OPJ Global University
Master’s Degree in Artificial Intelligence and Data Science
Liverpool John Moores University
Master of Science in Machine Learning & AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIExecutive Certificate

IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership ProgrammeIIIT Bangalore
Executive Programme in Generative AI for Leaders
upGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceOffline Bootcamps

upGrad
Data Science and AI-MLDoctorate
For All Domains
IIITB & IIM, Udaipur
Chief Technology Officer & AI Leadership Programme
Swiss School of Business and Management
Global Doctor of Business Administration from SSBM
Edgewood University
Doctorate in Business Administration by Edgewood UniversityGolden Gate University
Doctor of Business Administration From Golden Gate University
Rushford Business School
Doctor of Business Administration from Rushford Business School, SwitzerlandGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)-d9bdeff6165f4eb1ba2adcebde78e961.svg)
University of Waterloo
Chief Technology and AI Officer ProgramLeadership / AI
Golden Gate University
DBA in Emerging Technologies with Concentration in Generative AIMachine Learning
Machine Learning
Data Science
Degree / Exec. PG
O.P Jindal Global University
Master’s Degree in Artificial Intelligence and Data ScienceIIIT Bangalore
Executive Diploma in Data Science & AILiverpool John Moores University
Master of Science in Data ScienceExecutive Certificate
upGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftupGrad | Microsoft
Gen AI Mastery Certificate for Data AnalysisupGrad | Microsoft
Gen AI Mastery Certificate for Software DevelopmentupGrad | Microsoft
Gen AI Mastery Certificate for Managerial ExcellenceupGrad | Microsoft
Gen AI Mastery Certificate for Content CreationOffline Bootcamps
upGrad
Data Science and AI-MLupGrad
Data AnalyticsMBA
Masters

Liverpool School of Business
Master of Business Administration from Liverpool Business School with IIM Udaipur Certification
Paris School of Business
Master of Science in Business Management and TechnologyO.P.Jindal Global University
MBA (with Career Acceleration Program by upGrad)Edgewood University
MBA from Edgewood UniversityO.P.Jindal Global University
MBA from O.P.Jindal Global UniversityGolden Gate University
Master + Doctor of Business Administration (MBA+DBA)Executive Certificate

IMT, Ghaziabad
Advanced General Management ProgramMarketing
Executive Certificate
Offline Bootcamps
upGrad
Digital MarketingManagement
Degree
O.P Jindal Global University
MSc in International Accounting & Finance (ACCA integrated)
Golden Gate University
Master of Arts in Industrial-Organizational PsychologyExecutive Certificate

IIIT-B & IIM, Udaipur
Chief Technology Officer & AI Leadership ProgrammeIIIT-B & IIM, Udaipur
Chief Data and AI Officer Programme
IIM Kozhikode
Human Resource Analytics Course from IIM-KupGrad | Microsoft
Gen AI Foundations Certificate Program from MicrosoftEducation
Education

Northeastern University
Master of Education (M.Ed.) from Northeastern UniversityEdgewood University
Doctor of Education (Ed.D.)Edgewood University
Master of Education (M.Ed.) from Edgewood UniversityCertifications
Project Management
Certification

Knowledgehut
Leadership And Communications In ProjectsKnowledgehut
Microsoft Project 2007/2010-ae8d039bbd2a41318308f8d26b52ac8f.svg)
Knowledgehut
Financial Management For Project ManagersKnowledgehut
Fundamentals of Earned Value Management (EVM)Knowledgehut
Fundamentals of Portfolio ManagementKnowledgehut
Fundamentals of Program Management-35c169da468a4cc481c6a8505a74826d.webp&w=128&q=75)
Knowledgehut
CAPM® CertificationsKnowledgehut
Microsoft® Project 2016Certifications & Trainings
-7f4b4f34e09d42bfa73b58f4a230cffa.webp&w=128&q=75)
Knowledgehut
PMP® CertificationKnowledgehut
PMI-RMP® CertificationKnowledgehut
PMP Renewal Learning PathKnowledgehut
Oracle Primavera P6 V18.8Knowledgehut
Microsoft® Project 2013Knowledgehut
PfMP® Certification CourseKnowledgehut
Project Planning and MonitoringPrince2 Certifications

Knowledgehut
PRINCE2® FoundationKnowledgehut
PRINCE2® PractitionerKnowledgehut
PRINCE2 Agile Foundation and PractitionerKnowledgehut
PRINCE2 Agile® Foundation CertificationKnowledgehut
PRINCE2 Agile® Practitioner CertificationManagement Certifications
Knowledgehut
Project Management Masters Certification ProgramKnowledgehut
Change ManagementKnowledgehut
Project Management TechniquesKnowledgehut
Product Management Certification ProgramKnowledgehut
Project Risk Management- Study abroad
- Offline centres
- uGSOT - B.Tech
More
%20(2)-db0b6f38da9c485faf76e366793c9b9e.webp&w=128&q=75)



Artificial Intelligence Courses
The best Artificial Intelligence courses help you move from basic concepts to building and deploying real AI systems. You gain Generative AI skills and prepare for job-ready roles across industries.
Learn from faculty at globally top-ranked universities
Earn an average salary hike of 51% after completion
-d365049d54604e59b9241feaed93b89e.webp&w=3840&q=75)
1:1 Coaching
Mock Interviews
Access to Job Portal





Our Top University Partners
How AI-Ready Is Your Career?
The work you do today may already be easy for AI to replace. Find out where you truly stand.
Automation risk in your profile
Skill relevancy for AI roles
Ability to adapt
🧠 Discover how future-ready your career really is
-d7bcc89c78df4cff8b2140ff79f1ffb1.webp&w=1200&q=75)
Artificial Intelligence (AI) Course Projects: Learn by Doing
17+
Projects


















Learn Artificial Intelligence From The Best Instructors
8
Instructors
8
Industry Experts























-39a9e7a7278a441ea08a60a1f45b4913.png&w=128&q=75)
Services to Help You Achieve Your Goal
Access the various career developement support services offered by upGrad to help you achieve your professional goals
Receive unparalleled guidance from industry mentors, teaching assistants, and graders


What Our Learners Have To Say About Artificial Intelligence Course





Latest AI Industry Trends
The AI Industry is growing rapidly and is expected to continue to do so in the coming years. As Artificial Intelligence becomes more sophisticated and accessible, it is likely to have a major impact on all industries
95%
Businesses expect AI to have a positive impact on their industry in the next five years
37%
Organisations have adopted AI
16%
Expected to replace all US jobs in less than half a decade
77%
Businesses are using AI for automation
Artificial Intelligence Course Overview
Work is evolving rapidly for engineers, products, and businesses.
AI does not simply answer questions. It can plan, operate, and even connect to tools, and it can deliver results with minimal human intervention. This evolution is defining the future of Artificial Intelligence.
upGrad provides Artificial Intelligence courses for working professionals looking to adapt to this evolution. If you are a software developer, a data professional, or a business owner, you can learn how to apply Artificial Intelligence to your work.
This course focuses on practical skills that can be applied to your work.
What is Artificial Intelligence?
Artificial Intelligence (AI) is a simulation of human intelligence by computers to perform tasks including understanding language, solving problems, recognizing patterns, and making decisions.
Artificial Intelligence learns from data and uses that learning to give results. Unlike basic programs that follow fixed rules, AI can improve over time and handle new situations.
Some of the most common Artificial Intelligence systems include GPT-4, Claude, Gemini, Llama, and several others. These systems can understand, write, code, summarize, translate, and perform various functions.
Real Life Use Cases of Artificial Intelligence
Artificial Intelligence works across many industries and helps you to complete tasks faster and with better accuracy. Some key uses of AI are:
- Product: It helps you build smart features, improve user experience, automate testing, and track how users interact with your product.
- Banking: It helps you assess risk, detect unusual activity, automate checks, and support faster decision-making.
- Retail: It helps you to understand customer behavior, recommend products, manage demand, and improve inventory planning.
- Healthcare: It helps you to study patient data, assist in diagnosis, support treatment planning, and monitor patient progress.
- Marketing: It helps you to understand audience needs, improve targeting, create better campaigns, and track performance.
- Operations: It helps you analyze data, improve processes, reduce manual work, and support daily business decisions.
Who Should Take an Artificial Intelligence Course?
Artificial Intelligence courses suit you if you want to apply AI in your current job and improve your skills.
You will learn how AI works in real settings and how to use it to handle tasks, improve decisions, and solve problems.
Tech Professionals
If you work in software, data, or AI and want to move ahead in your career, these artificial intelligence and machine learning courses will help you take on more complex work. You can:
- Create smarter applications using AI
- Solve real business problems with data
- Step into more advanced technical roles
System Designers and Team Leads
If you design systems or manage teams, these artificial intelligence online courses help you create strong AI systems and guide projects better. You can:
- Structure AI systems for real use
- Guide teams on AI-focused projects
- Make better technical decisions
Product Managers and Business Heads
If you handle products or business goals, these artificial intelligence and machine learning courses help you use AI in everyday work. You can:
- Use data to guide product decisions
- Simplify daily operations with AI
- Improve outcomes across teams
Beginners and Early Professionals
If you are starting out and know basic Python, these artificial intelligence online courses help you build your foundation step by step. You can:
- Learn how AI works from scratch
- Practice with simple projects
- Build confidence in using AI tools
Industry Professionals (Marketing, Finance, Cybersecurity, etc.)
If you work in areas like marketing, finance, or cybersecurity, these courses help you bring AI into your work. You can:
- Apply AI in your daily tasks
- Get deeper insights from your data
- Keep your skills current in your field
Why Choose Artificial Intelligence Courses in 2026?
Learning Artificial Intelligence in 2026 is not just about keeping up; it is about staying relevant in your career. Companies now use AI in real workflows, and they need people who can build, manage, and improve these systems, not just use simple and basic tools.
AI is no longer limited to testing or small projects. Businesses now use it in daily operations, products, and decision-making. When you learn AI skills, you can create solutions that companies actually need.
Here are some reasons why professionals are choosing Artificial Intelligence courses in 2026:
- AI-related job roles in India are experiencing massive growth, projected to surge by up to 45% in FY26
- Nearly 60% of Indian firms use at least one form of Artificial Intelligence (AI) in business operations
- AI adoption in enterprises is expected to cross 55% in the next few years
- By 2027, it is projected that half of all business decisions will be augmented or automated by AI agents.
In simple terms, learning Artificial Intelligence can help you:
- Gain skills that companies look for today
- Work on real AI systems instead of basic tools
- Move into roles with better career growth
- Stay competitive in a fast-changing job market
What You Will Learn in Artificial Intelligence Online Courses?
Artificial Intelligence courses help you move from basic understanding to building systems that can learn, make decisions, and solve problems on your own.
These programs combine core concepts, hands-on practice, and real use cases, so you can apply what you learn in real work.
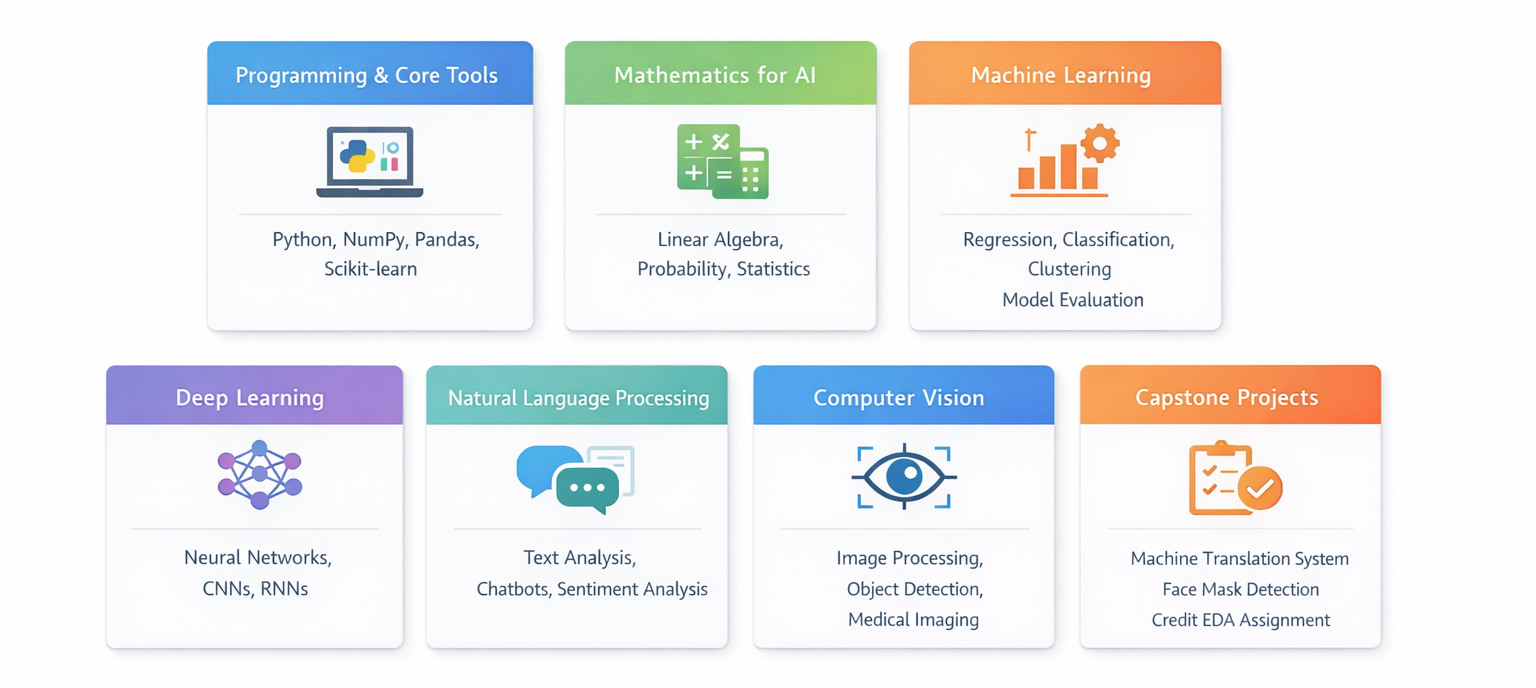
Tools and Technologies Covered in Artificial Intelligence Courses
From cloud platforms to AI frameworks, here are the tools you will learn:
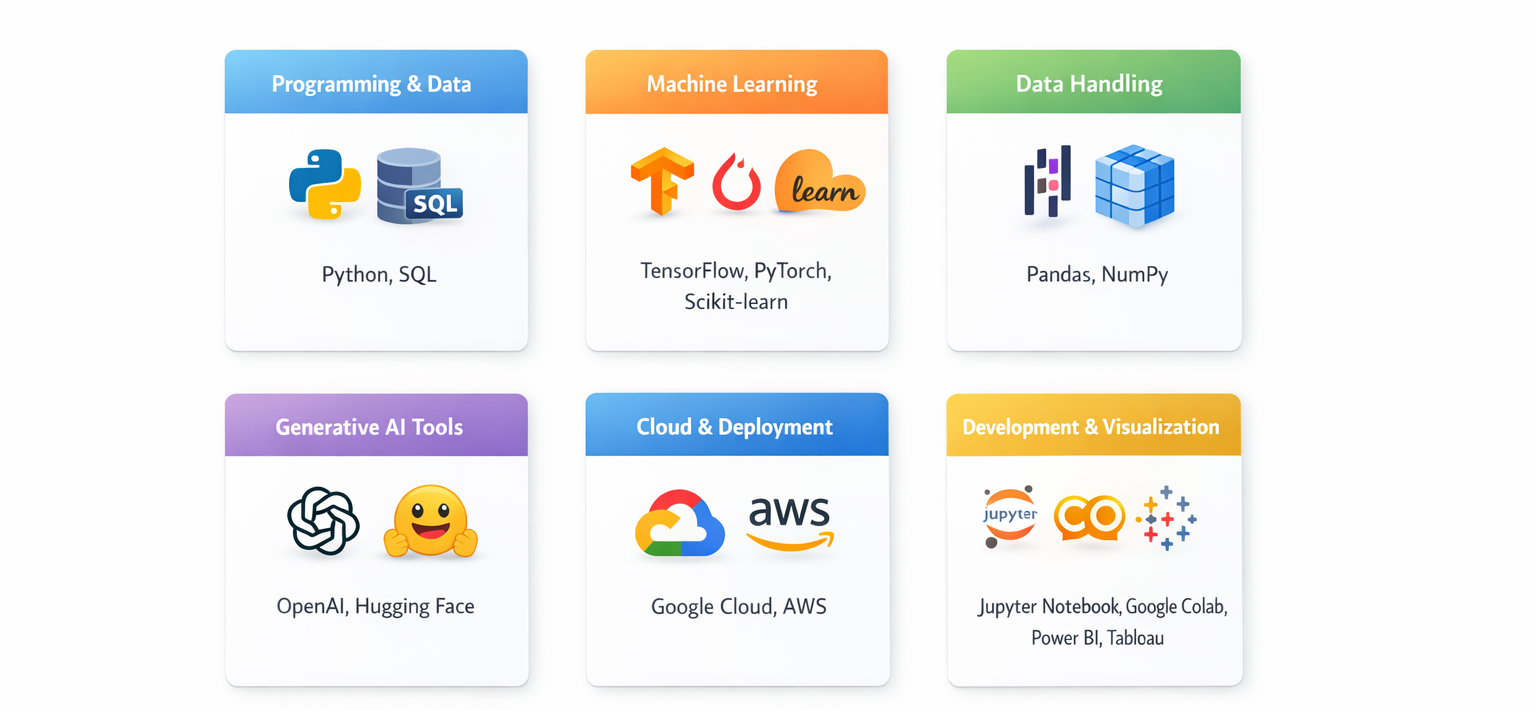
Hands-On Projects in upGrad Artificial Intelligence Courses
You cannot learn Artificial Intelligence with theory alone. You need to build real projects to understand how it works. Employers also look at what you can create, not just what you know.
These courses include hands-on projects that help you apply your learning and build a strong portfolio.
1. Credit EDA Assignment
You will analyze credit data to find patterns, clean datasets, and study trends. This project helps you understand risk factors and build strong data analysis skills using real datasets.
Skills you learn: Data analysis, Pandas, NumPy, data cleaning, visualization
2. Model Selection Case Study – Telecom Churn
You will build and compare models to predict customer churn. This project helps you evaluate performance, select the best model, and understand how businesses reduce customer loss.
Skills you learn: Classification models, model evaluation, feature selection, Scikit-learn
3. Face Mask Detection
You will build a model that detects whether people wear masks using image data. This project helps you understand computer vision and apply deep learning to real-world safety problems.
Skills you learn: Computer vision, CNN, TensorFlow/Keras, image processing
4. Machine Translation System
You will create a system that converts text from one language to another. This project helps you understand language models and how AI processes and generates human language.
Skills you learn: NLP, sequence models, text processing, deep learning
5. News Recommender System
You will design a system that suggests news based on user interests. This project helps you understand recommendation logic and how platforms personalize content for better user experience.
Skills you learn: Recommendation systems, user behavior analysis, data filtering
6. Gesture Recognition
You will develop a system that identifies human gestures from video data. This project helps you learn how AI understands movement and applies deep learning to visual recognition tasks.
Skills you learn: Deep learning, video processing, CNN/RNN, pattern recognition
Career Outcomes After an Artificial Intelligence Course: Salaries and Roles
The job market for Artificial Intelligence professionals in India is growing fast. Companies offer strong salaries because they need skilled people.
Many industries such as IT services, banking, e-commerce, healthcare, and consulting actively hire AI professionals. Companies build dedicated teams to solve real business problems.
The demand for skilled professionals is much higher than the number of people available. This creates more job opportunities and better salary growth for those with the right skills.
Here are some of the top roles that you can explore once you complete your course.
Role | What You Will Do | Average Salary in India (₹ LPA) |
Computer Vision Engineer | Develop systems that process images and videos, work on detection, recognition, and visual data tasks | ₹5 – 11 LPA |
NLP Engineer | Build systems for text analysis, chatbots, and language understanding using AI models | ₹6 – 12 LPA |
AI Engineer | Design AI systems, integrate models into applications, and improve performance using real-world data | ₹6 – 15 LPA |
Machine Learning Engineer | Build and train machine learning models, manage data pipelines, and deploy models into real applications for predictions and decisions | ₹7 – 18 LPA |
Data Scientist | Analyze large datasets, create models, and generate insights to solve business problems and support decisions | ₹7 – 18 LPA |
AI Solutions Architect | Design end-to-end AI systems, choose tools, and guide teams in building and deploying AI solutions | ₹14 – 37 LPA |
Note: These salary figures are based on data from Glassdoor and may vary depending on experience, location, and company.
Industries Hiring Artificial Intelligence Professionals
Companies across many industries hire professionals with Artificial Intelligence skills.
- IT Services and Software Products: Build products, improve systems, and handle large applications.
- Banking, Financial Services, and Insurance: Manage risk, detect fraud, and support customer services.
- E-commerce and Retail: Recommend products, manage inventory, and improve user experience.
- Healthcare and Life Sciences: Support diagnosis, manage data, and assist research.
- Consulting and Professional Services: Analyze data and support business decisions.
- Media and Content Platforms: Manage content and personalize user experience.
Everything You Need to Know About Artificial Intelligence
Frequently Asked Questions about AI Course
1. What is an artificial intelligence course online?
Online artificial intelligence courses teach you how Artificial Intelligence works, how machines learn from data, recognize patterns, and make decisions.
How you learn
- Video lessons that explain concepts step by step
- Coding labs where you build and test models
- Practical exercises to apply what you learn
- Real-world projects based on actual use cases
What you learn
- Basics of machine learning and deep learning
- Data preprocessing and feature engineering
- Model building, training, and evaluation
- Working with tools like Python, TensorFlow, and NLP libraries
- Solving real problems like prediction, classification, and automation
Programs from upGrad also include mentorship and guided support, so you build practical AI skills, not just theory.
2. What topics are covered in AI courses online?
Most AI courses cover both basics and advanced concepts in Artificial Intelligence.
Core topics you learn
- Statistics and probability for data analysis
- Data preprocessing and feature engineering
- Machine learning algorithms and model building
- Neural networks for intelligent systems
Advanced topics in many programs
- Deep learning, NLP, and computer vision
- Generative AI and modern LLM applications
- Model deployment for real-world use
You learn how to build, evaluate, and apply AI models to solve real industry problems.
3. Can someone learn AI fully online without classroom sessions?
Yes, many learners successfully complete AI programs entirely online. Reputable programs provide recorded lectures, live classes, coding labs, assignments, and mentor support through digital platforms. Learners interact with instructors and peers through discussion forums and virtual sessions.
Online learning platforms like upGrad offers flexibility for working professionals and students.
4. How long does it take to complete an AI course online?
The duration depends on the level of the Artificial Intelligence course and how deeply it covers the subject.
Typical timelines
- Beginner certificate courses: 3–6 months
- Advanced diploma or postgraduate programs: 9–18 months
- Master’s degree programs: up to 2 years
Most programs from upGrad follow a structured schedule, so you can learn part-time while continuing your job.
5. How much time per week is needed for an AI course?
Most AI courses require about 8–12 hours of study per week. This time usually includes watching lectures, practicing coding, completing assignments, and revising concepts.
Advanced programs with complex projects may require up to 15 hours per week. Many working professionals study during evenings or weekends, and consistent weekly practice helps learners understand AI concepts more effectively.
6. Does someone need coding experience to start an AI course?
No. Many beginner AI courses do not require prior coding experience. These programs usually introduce programming basics before moving into machine learning topics.
Learners with logical thinking and problem-solving skills often adapt faster. Some intermediate or advanced programs may expect basic programming familiarity. upGrad AI courses start with foundational concepts, allowing beginners to learn coding and AI concepts step by step.
7. Should someone learn Python before an AI course?
Learning basic Python before starting an AI course can make the journey much smoother. Python is the most commonly used language in AI because it supports popular machine learning and data libraries.
Understanding basic concepts like syntax, loops, and functions allows you to focus on AI topics rather than learning programming from scratch. Even if you’re new to coding, many upGrad AI programs include Python fundamentals, so beginners can start learning AI without prior programming experience.
8. What programming languages should learners learn for AI courses?
AI courses typically teach programming languages that are essential for data analysis, model building, and AI applications.
Common languages include:
- Python – Used for machine learning, deep learning, and AI development.
- R – Focused on statistical analysis and data modeling.
- SQL – For managing databases and running data queries.
Most upGrad AI programs emphasize Python, along with the tools and libraries needed to build and deploy AI models effectively.
9. Is math required for taking an AI online course?
Yes. Artificial Intelligence uses math to explain how models learn from data.
What math is involved
- Statistics and probability
- Linear algebra basics
- Basic calculus (in some topics)
What you actually need
- You don’t need advanced math to start
- Most beginner courses teach required concepts step by step
Programs from upGrad introduce these concepts gradually while you work on real AI projects.
10. What common mistakes do beginners make in AI courses?
Many beginners focus only on theory without practicing coding regularly. Some skip foundational topics like data preprocessing or statistics. Others try advanced models too early without understanding basics. Many learners also fail to build project portfolios. Successful learners stay consistent, practice regularly, and apply concepts through real datasets.
11. What algorithms do learners study in an AI course?
AI courses cover algorithms that help machines learn patterns and make predictions in Artificial Intelligence.
Common algorithms you study
- Regression models for prediction tasks
- Decision trees for classification and decision-making
- Clustering algorithms for grouping similar data
- Support Vector Machines (SVM) for classification
- Ensemble methods that combine multiple models
Advanced topics in some programs
- Neural networks for complex pattern recognition
- Deep learning architectures for large-scale AI tasks
Programs from upGrad also include these advanced concepts with practical projects, so you learn how to apply them in real scenarios.
12. Do learners study neural networks and deep learning?
Yes, most comprehensive programs teach neural networks and deep learning. Learners understand how multi-layer models process complex data such as images, speech, and text. Advanced topics include convolutional networks, recurrent networks, and transformer architectures.
13. How do AI courses teach large language models?
AI courses teach how large language models work by combining concepts with hands-on practice.
What you learn
- Basics of LLMs and how they process language
- Transformer architecture, embeddings, and attention mechanisms
- How models understand context and generate responses
How you learn
- Work with pretrained models
- Practice prompt engineering techniques
- Build small applications using LLMs
Programs from upGrad teach these concepts through practical examples and projects, so you understand how to apply LLMs in real use cases.
14. Do AI courses cover generative AI and large language models?
Yes, many modern AI courses now include modules on generative AI and large language models (LLMs). Learners get to explore areas like text generation, conversational AI systems, and creative AI applications.
Advanced programs go further, offering in-depth training on generative model architectures and showing how LLMs are applied to build intelligent applications. Many upGrad AI programs also cover these topics, helping learners gain both theoretical knowledge and practical experience with generative AI tools.
15. What AI tools do learners use in courses?
AI courses give learners hands-on experience with industry-standard tools used for data analysis, model building, and experimentation. These tools help bridge the gap between theory and practical work.
Common tools include:
- Jupyter Notebook / Google Colab – For writing and testing code.
- Data visualization libraries – Such as Matplotlib and Seaborn.
- Machine learning libraries – Like Scikit-learn for model development.
- Cloud platforms – For training large-scale models.
- Version control systems – Git and GitHub for managing projects.
Using these tools, learners gain practical skills that are essential in real-world AI and machine learning environments.
16. What frameworks like TensorFlow or PyTorch are taught?
Most AI programs teach deep learning frameworks that help learners build and train complex neural networks efficiently. TensorFlow and PyTorch are the most widely used frameworks in industry and research.
Learners typically use these frameworks to:
- Design neural network architectures
- Train models using large datasets
- Optimise performance through tuning
- Test and validate predictions
- Deploy trained models into applications
Understanding these frameworks allows learners to build production-ready AI solutions and work with modern deep learning systems.
17. How do AI courses teach data preprocessing?
AI courses teach data preprocessing as a critical step before model training. Learners understand that clean and well-structured data directly improves model accuracy and reliability.
Programs usually train learners to:
- Handle missing or inconsistent data
- Remove noise and outliers
- Transform and scale variables
- Encode categorical features
- Engineer meaningful input features
18. How do AI courses teach model evaluation?
AI courses teach you how to check if your model works well in Artificial Intelligence.
What you learn
- Accuracy to measure overall correctness
- Precision and recall for classification quality
- F1 score for balanced evaluation
- Confusion matrix to analyze errors
- Cross-validation to test performance on new data
You use these metrics on real projects to see how your model performs and improve it.
19. Do learners study AI model deployment?
Yes, advanced AI programs teach how to deploy models into real-world environments where users or systems can access them. Deployment transforms a trained model into a functional application.
Learners usually practice:
- Creating APIs to serve predictions
- Using cloud platforms for hosting models
- Packaging models with containers
- Monitoring performance after deployment
20. Do AI courses teach practical projects with real data?
Yes, strong AI programs prioritise learning through real-world datasets and problem-solving scenarios. Instead of working only with theory, learners build solutions similar to those used in industry.
They typically work on:
- Predictive analytics using business data
- Classification models for decision-making
- Automation and recommendation systems
Working with real data helps learners understand practical challenges such as noise, bias, and scalability, which prepares them for professional AI roles.
21. Which AI courses focus on hands-on learning?
Career-focused AI programs focus on practical learning rather than just theory. They provide structured environments where learners can practice skills in ways similar to real workplace scenarios.
These programs usually include:
- Coding labs and guided exercises – Practice programming in a controlled setting.
- Industry-style assignments – Work on tasks that reflect real business problems.
- Experimenting with real datasets – Learn how to handle and analyze real-world data.
- Mentor feedback on projects – Get guidance to improve your work and understanding.
- Applied case studies – See how concepts are used to solve actual business challenges.
Programs offered by upGrad follow this approach, helping learners gain practical skills that prepare them for jobs rather than only learning concepts.
22. What projects do learners build in an AI course?
AI learners build practical projects that demonstrate how intelligent systems solve real problems. These projects help them apply algorithms, data processing, and model evaluation techniques together.
Common project examples include:
- Product recommendation systems
- Fraud detection models
- Customer segmentation analysis
- Chatbots and conversational AI
- Image classification and object detection
23. Do AI courses include capstone or real-world projects?
Many advanced AI programs include a capstone project as the final assessment. A capstone project brings together everything you have learned and applies it to a real-world problem.
In a typical capstone project, learners:
- Define a problem – Identify a real business or technical challenge.
- Collect and prepare data – Clean and organize data for analysis.
- Build and evaluate models – Create solutions and test how well they perform.
These projects help learners apply their knowledge in a practical way and build a strong portfolio for job opportunities.
24. Do projects help build a portfolio?
Yes, project work is the foundation of a strong professional portfolio. Employers often look for practical experience rather than only theoretical knowledge, especially for technical roles. A good AI portfolio clearly shows your coding ability, problem-solving skills, understanding of how models are built and evaluated, and your ability to explain results in a simple way.
When your projects are well-documented and easy to understand, they create a strong impression during interviews. This significantly improves your chances of getting job opportunities and growing your career.
25. Do AI courses teach business applications?
Yes, most modern AI programs show how organizations use AI to make better decisions and work more efficiently. Learners learn how data-driven models can solve real business problems.
Common applications include:
- Customer behavior prediction – Understanding and anticipating customer needs.
- Process automation – Streamlining repetitive tasks.
- Risk assessment – Identifying potential issues before they occur.
- Personalized recommendations – Suggesting products or services tailored to users.
- Demand forecasting – Predicting future demand for products or services.
26. Are ethics and responsible AI part of AI training?
Yes, responsible AI is now an essential part of most professional programs. Learners study how AI systems affect people, organisations, and society.
Ethics modules typically cover:
- Data privacy and security
- Transparency and accountability
- Responsible model design
- Regulatory considerations
27. How do courses address fairness and bias in AI systems?
AI courses also teach how bias in data can affect results and decision-making. Learners understand why biased data leads to unfair outcomes and how to handle these issues in real applications.
They usually study key areas such as sources of bias in datasets, methods to measure fairness, and techniques to reduce bias in models. Courses also cover model transparency, which helps explain how decisions are made. This knowledge is important for building responsible AI systems that produce fair and reliable outcomes.
28. What AI courses offer certificates upon completion?
Many AI courses provide certificates once you finish the training and assessments.
From upGrad, you can explore:
- Generative AI Foundations Certificate Program
- Certification Program in Artificial Intelligence and Machine Learning
What you get along with the certificate:
- Hands-on projects to show your skills
- Real-world assignments based on AI use cases
- Practical experience you can add to your portfolio
You don’t just complete lessons. You finish with proof of your skills.
29. Are there AI courses focused on natural language processing?
Yes. Many AI courses focus on Natural Language Processing, where you learn how machines understand and generate human language.
Courses from upGrad include:
- Introduction to Natural Language Processing (Free Course)
- PG Certification in Machine Learning and NLP (IIIT Bangalore)
- AI and Data Science programs with NLP modules
What you learn:
- Text preprocessing and sentiment analysis
- Named Entity Recognition (NER)
- Building language models using Python and libraries like spaCy
These courses focus on real applications like chatbots, text analysis, and language-based AI systems.
30. Which AI course is best for beginners?
Some courses for beginners introduce the basics of AI and tools before moving to the advanced level.
Some beginner courses on AI offered by upGrad include:
- Generative AI Foundations Certificate Program – Introduces core AI concepts and tools like ChatGPT and Copilot.
- Artificial Intelligence and Machine Learning Certification Program – Covers Python, ML basics, and real-world AI projects.
- Executive Diploma in Machine Learning and AI (IIIT Bangalore) – A deeper program covering algorithms, model training, and industry applications.
Some beginner courses on AI start with the basics of AI, Python, and machine learning.
31. What is the difference between AI and generative AI courses?
The difference mainly comes down to the scope and focus of the training.
AI courses cover a wide range of artificial intelligence topics. They help learners understand how AI systems work and how they are used in real-world applications. These courses usually include:
- Machine learning algorithms
- Deep learning models
- Data analysis and model training
- Building AI systems for prediction and automation
On the other hand, generative AI courses focus on a specific area of AI that creates new content. These programs are more specialized and typically include:
- Large Language Models (LLMs)
- Prompt engineering
- Generating content like text, images, and code
- Building applications using generative AI tools
32. What courses teach AI for computer vision?
Several AI courses now include computer vision modules that teach how machines analyze images and videos using deep learning and machine learning techniques.
Examples of such programs:
- Executive Diploma in Machine Learning and AI (IIIT Bangalore) – upGrad
Covers neural networks, deep learning, and image-based applications like object detection and recognition. - Master of Science in Machine Learning and AI (Liverpool John Moores University)
Focuses on advanced models for computer vision tasks. - Deep Learning for Computer Vision courses
Teach CNNs, image classification, facial recognition, and video analysis using frameworks like TensorFlow or PyTorch.
33. Are there AI courses for robotics applications?
Yes. upGrad AI courses introduce concepts used in robotics applications, especially in areas where AI systems interact with physical environments.
Learners study topics such as:
- Machine learning algorithms used in intelligent systems
- Computer vision for object detection and visual recognition
- Sensor data processing for real-world environments
- Automation and decision-making systems
These skills help learners understand how AI technologies support robotics in fields such as manufacturing, autonomous systems, and smart devices.
34. What study resources should learners use alongside an AI course?
You can improve your AI learning by using extra resources along with your course. These help you understand concepts better and build practical skills.
Helpful resources include:
- Books on AI and machine learning – To learn core concepts and theory.
- Research papers and technical blogs – To stay updated with new developments.
- GitHub repositories – To explore real projects and code examples.
- Online coding platforms – To practice Python and machine learning problems.
Learners in upGrad AI programs often use these resources along with course projects to gain deeper understanding and improve practical skills.
35. Can AI course projects boost someone’s portfolio?
Yes. AI course projects play a major role in building a strong professional portfolio. They show that you can apply AI concepts to solve real problems.
Portfolio projects may include:
- Machine learning model development
- Data analysis and prediction systems
- Computer vision or NLP applications
- AI automation tools or intelligent assistants
Projects completed in upGrad AI programs help learners demonstrate practical experience and showcase their skills to employers.
36. Are there AI courses from top universities online?
Yes, many AI courses are offered online in collaboration with top universities, allowing you to earn recognized credentials while studying from home.
Examples available through upGrad include:
- Executive Diploma in Machine Learning and AI with International Institute of Information Technology Bangalore
- Master of Science in Machine Learning and AI with Liverpool John Moores University
- AI and Data Science programs with O.P. Jindal Global University
These programs combine university-level learning, industry projects, and flexible online formats, making it easier for professionals to study AI without attending on-campus classes.
37. What kind of projects will someone build in an AI course?
AI courses include hands-on projects where you apply concepts from Artificial Intelligence to real problems.
Typical projects you build
- Predictive models (sales forecasting, demand prediction)
- Recommendation systems for products or content
- Chatbots and conversational AI applications
- Computer vision projects (image classification, object detection)
- NLP projects like sentiment analysis
Programs from upGrad focus on project-based learning, so you build a strong portfolio that shows your practical AI skills.
38. How are datasets and data preprocessing covered in AI courses?
AI courses teach you how to prepare raw data before building models in Artificial Intelligence.
What you learn
- Collect and load datasets
- Clean data and handle missing values
- Scale and normalize features
- Encode categorical variables
- Split data into training and testing sets
You work with real datasets and follow the same steps used in actual machine learning workflows. Programs from upGrad include hands-on exercises, so you practice preprocessing data before training models.
39. What advanced topics follow AI basics?
After learning foundational machine learning concepts, learners typically move into specialised and more complex areas of AI.
Common advanced topics include:
- Deep learning and neural networks
- Natural language processing
- Computer vision
- Reinforcement learning
- Generative AI models
These areas allow learners to build sophisticated intelligent systems used in cutting-edge applications.
40. Which advanced AI topics lead to higher pay jobs?
Certain AI specialisations are in particularly high demand and often lead to higher-paying roles due to their technical complexity and business impact.
High-value specialisations include:
- Deep learning engineering
- MLOps and model deployment
- Generative AI development
- Large-scale data modelling
Professionals with expertise in these areas often work on complex systems that directly influence organisational performance.
41. Are NLP specialisation courses available?
Yes, many AI programs offer specialised training in natural language processing. NLP focuses on enabling machines to understand and generate human language.
Platforms like upGrad also offer beginner-friendly NLP learning options, including the course “How ChatGPT Understands You: Intro to NLP.” This program helps learners understand how modern language models process text, interpret intent, and generate human-like responses, making it a practical starting point for anyone interested in conversational AI.
42. Are computer vision courses available?
Yes, learners can specialise in computer vision, which focuses on enabling machines to interpret visual information from images and videos.
Computer vision courses typically cover:
- Image classification and object detection
- Facial recognition systems
- Video analysis and tracking
- Medical image analysis
43. Can reinforcement learning be learned online?
Yes, many advanced AI programs teach reinforcement learning through structured theory and simulation-based practice. Learners study how intelligent agents make decisions by interacting with environments and receiving rewards or penalties. Courses typically cover policy optimisation, value functions, and training techniques.
Online platforms like upGrad often use simulated environments such as game scenarios or control systems so learners can experiment safely. With guided projects and mentor support, learners can understand how reinforcement learning powers robotics, recommendation engines, and autonomous systems.
44. Are robotics AI courses available?
Yes, some specialised programs combine artificial intelligence with robotics and automation technologies. These courses focus on how intelligent algorithms control machines that interact with physical environments. Learners typically study perception systems, motion planning, and decision-making models used in robotics.
Many programs include simulation tools that allow learners to design and test robotic behaviours virtually. Robotics-focused AI education is especially useful for careers in manufacturing automation, autonomous vehicles, and industrial robotics.
45. Can learners specialise in AI by industry?
Yes, many advanced AI programs offer industry-specific learning tracks that apply AI techniques to real business domains. This helps learners develop practical expertise aligned with sector needs.
Common industry specialisations include:
- Healthcare analytics and medical imaging
- Financial risk modelling and fraud detection
- Retail demand forecasting and recommendation systems
- Manufacturing automation and predictive maintenance
Industry-focused training helps learners understand domain data, regulations, and business challenges, which improves job readiness.
46. What are the best online platforms for Artificial Intelligence Courses?
Strong platforms for Artificial Intelligence focus on structured learning, hands-on practice, and recognized certification.
One option is upGrad, which offers programs in collaboration with:
- IIIT Bangalore
- Liverpool John Moores University
What you get in these programs:
- Structured curriculum from basics to advanced topics
- Hands-on projects based on real use cases
- Mentorship and expert guidance
- Career support to help you move into AI roles
These platforms focus on helping you build practical AI skills, not just theoretical knowledge.
47. Are university-certified AI courses available online?
Yes, many universities now offer fully online AI programs with recognised academic credentials. These programs follow structured curricula, formal assessments, and certification standards similar to on-campus learning. University-certified courses often carry greater professional credibility and may support long-term academic progression.
Platforms like upGrad collaborate with leading institutions such as IIIT Bangalore, Liverpool John Moores University, and Indian Institute of Management Udaipur to deliver university-certified AI programs online. These partnerships allow learners to gain accredited qualifications along with industry-relevant practical training.
48. Do AI courses provide certificates?
Most structured AI programs award completion certificates after learners finish required modules and assessments. These certificates confirm that learners have completed formal training in specific AI skills. While certificates alone do not guarantee employment, they strengthen professional credibility when combined with strong project experience and technical knowledge.
49. How should someone choose the right AI course?
Learners should choose programs carefully, keeping their long-term career goals and learning style in mind. A good course balances theory, practical training, and career support.
Key factors to consider include:
- Curriculum depth and relevance – Covers the skills needed in today’s industry.
- Hands-on projects – Opportunities to apply concepts in real scenarios.
- Mentorship and academic support – Guidance from experts throughout the course.
- Industry recognition – Certificates valued by employers.
- Career services – Support with placements, resume building, and interviews.
50. Do AI courses include mentorship and academic support?
Yes. Many Artificial Intelligence courses include mentorship and support to help you stay on track.
What you typically get
- Guidance from industry experts or faculty mentors
- Live doubt-clearing sessions and discussion forums
- Feedback on assignments and projects
Programs from upGrad also offer structured mentorship, so you can understand concepts better and improve your project work.
51. What jobs are available after completing an AI course?
An Artificial Intelligence course opens roles based on your skills and project experience.
Common roles you can target
- AI Engineer
You build and deploy AI systems, integrate models into apps, and handle real-world automation tasks - Machine Learning Engineer
You design, train, and optimize models, and work on production pipelines - Data Scientist
You analyze data, build predictive models, and generate insights for business decisions - AI Analyst
You use AI tools and data analysis to support decision-making and reporting - Computer Vision Engineer
You work on image and video-based systems like object detection and facial recognition - NLP Engineer
You build systems that understand text, such as chatbots, sentiment analysis tools, and language models
Where you can work
- Tech companies and startups
- Finance, healthcare, and e-commerce
- Consulting and analytics firms
52. What entry-level roles are available after an AI course?
After completing an Artificial Intelligence course, you usually start with junior roles focused on hands-on work.
Common entry-level roles
- Junior Data Scientist
You work on data analysis, basic models, and support senior teams - Machine Learning Engineer Trainee
You assist in building and testing models, and learn deployment basics - AI Analyst
You analyze data, use AI tools, and help generate insights - Data Analyst (with AI exposure)
You work with data, dashboards, and apply basic ML techniques
What you gain in these roles
- Real project experience
- Exposure to tools, models, and workflows
- Skills that help you move into advanced roles
53. Which industries hire AI professionals the most?
AI talent is in demand across multiple sectors that rely on data-driven decision-making and automation.
Major hiring industries include:
- Technology and software services
- Banking and financial services
- Healthcare and diagnostics
- E-commerce and retail
- Manufacturing and logistics
As digital transformation expands, demand continues to grow across both traditional and emerging sectors.
54. Is an online AI course enough to become an AI engineer?
An online Artificial Intelligence course gives you a strong starting point, but it’s not enough on its own.
What the course helps you with
- Learn machine learning and model building
- Understand programming (mainly Python)
- Get exposure to real AI workflows
What you still need to do
- Build multiple real-world projects
- Improve your coding and problem-solving skills
- Create a strong portfolio (GitHub + case studies)
Programs from upGrad include hands-on projects to help you move toward job-ready skills, but your progress depends on how much you build and practice.
55. How do employers view online AI certifications compared to traditional degrees?
Employers increasingly focus on demonstrated skills rather than the learning format. They evaluate candidates based on project work, technical proficiency, and problem-solving ability. A well-recognised certification combined with strong practical experience can be as valuable as formal degrees for many technical roles, especially in fast-evolving fields like artificial intelligence.
56. Do AI course certificates help with job placement?
Yes. Certificates help, but only when you back them with real skills.
How certificates help you
- Show you’ve completed structured AI training
- Add credibility to your resume and LinkedIn profile
- Help you clear initial HR screening rounds
- Signal that you understand core AI concepts
Programs from upGrad focus on:
- Project-based learning with real scenarios
- Portfolio-ready assignments
- Practical exposure to AI tools and workflows
Certificates open the door. Your skills help you get the job.
57. How should learners prepare for AI job interviews after completing a course?
Effective preparation for AI roles requires a mix of theory and hands-on experience. To get ready, you should:
- Review core AI and machine learning concepts – Make sure you understand algorithms, models, and key principles.
- Practice Python coding basics – Be comfortable with syntax, loops, functions, and data handling.
- Explain your projects clearly – Highlight what you built, the approach you took, and the results achieved.
- Prepare real-world case studies – Show how you solved practical problems using AI techniques.
Projects completed in upGrad AI programs can serve as strong evidence of practical skills during technical interviews, helping you stand out to employers.
58. What is the average salary for AI professionals in India?
AI professionals in India typically earn between ₹6 lakh and ₹17 lakh per annum, depending on skill level and organisation. With experience, specialised expertise, and successful project delivery, salaries often increase significantly. Senior AI professionals and specialists in advanced domains such as deep learning or generative AI can earn substantially higher compensation.
59. Are AI skills in demand beyond 2026?
Yes, demand for AI professionals is expected to continue growing as organisations expand automation, predictive analytics, and intelligent decision systems. Businesses across industries are investing heavily in data-driven technologies, which ensures long-term career opportunities for skilled AI professionals.
60. Are scholarships or financial aid available for AI courses?
Yes, many AI programs offer financial support to make learning more accessible.
Common options include:
- Merit-based scholarships – For high-performing applicants.
- Need-based financial aid – For learners who qualify based on financial need.
- Early enrollment discounts – Limited-time fee reductions for early sign-ups.
- Flexible payment plans – Installments or EMI options to manage fees.
61. Can employers sponsor AI course fees?
Yes. Many companies sponsor Artificial Intelligence courses as part of upskilling.
When sponsorship is likely
- You work in tech, data, or analytics roles
- The course aligns with your job or team goals
How companies usually support
- Full or partial fee reimbursement
- Learning budgets for professional courses
- Approval for job-relevant certifications
62. Are flexible payment plans available for AI Courses?
Yes. Many Artificial Intelligence programs offer flexible payment options.
What you usually get
- EMI or instalment-based payment plans
- Low upfront cost with monthly payments
- Options suited for working professionals
63. Do AI courses provide lifetime access to learning material?
It depends on the Artificial Intelligence course and platform.
What you’ll usually see
- Some courses offer lifetime access to recorded lectures and resources
- Others give access for a limited time after completion
Why lifetime access helps
- You can revisit concepts anytime
- Review projects and code later
- Stay updated as AI tools and methods change
Access policies vary by platform, including programs from upGrad, so always check before enrolling.
64. Should learners choose free or paid AI courses?
It depends on what you want from Artificial Intelligence.
Free courses help you
- Learn basic concepts and terminology
- Explore AI without commitment
Paid courses help you
- Follow a structured learning path
- Work on real projects
- Get mentorship and guidance
- Access career support
If your goal is a job or career switch, paid programs, like those from upGrad, focus more on practical skills and industry projects.
65. Are MOOCs effective for learning AI?
MOOCs (Massive Open Online Courses) are a useful way to start learning AI. They offer flexible schedules and easy access to topics like machine learning, data basics, and AI concepts. Many well-known platforms such as Coursera and edX provide beginner-friendly courses created by top universities.
However, MOOCs often have some limitations:
- Limited personal mentorship or one-on-one guidance
- Less focus on structured, real-world projects
- Little or no career support like job placement or interview prep
Because of this, learners who want hands-on experience and clear career outcomes may prefer structured programs like upGrad AI courses. These programs usually include guided projects, expert mentorship, and dedicated career support, which can help learners build practical skills and prepare for job roles.
66. Is a paid AI course worth the investment?
Yes, if you choose the right Artificial Intelligence program and use it well.
Why it can be worth it
- You follow a clear, structured learning path
- You work on real projects, not just theory
- You build skills that match job requirements
- You improve your earning potential over time
What makes it valuable
- Hands-on projects and real use cases
- Mentorship and feedback
- Portfolio you can show to employers
Programs from upGrad include industry projects and practical training, which help you build job-ready skills. You get value when you actively build, practice, and apply what you learn.
67. What ROI can learners expect from AI education?
Return on investment depends on skill level, career transition success, and industry demand. Many professionals experience significant salary growth within two to three years after gaining job-ready AI skills. Long-term ROI remains strong because AI expertise continues to be highly valued across industries.
68. How should learners plan their AI learning roadmap?
A structured roadmap helps learners progress systematically from fundamentals to advanced specialisation. They should begin with programming basics and statistics, then move to machine learning concepts, and finally specialise in areas such as deep learning or NLP. Clear learning milestones and consistent practice improve long-term mastery.
69. What resources support AI learning alongside a course?
Learners strengthen understanding by using multiple complementary resources. These include technical documentation, coding practice platforms, research articles, and public datasets. Combining structured coursework with independent exploration deepens conceptual clarity and practical expertise.
70. How can learners practice AI skills outside coursework?
Learners can strengthen skills by applying knowledge to independent projects and real-world problems. Participating in online competitions, building predictive models, and experimenting with public datasets provides continuous practice. Regular experimentation helps learners move from theoretical understanding to practical expertise.
71. Should learners create a GitHub portfolio during the course?
Yes. Creating a GitHub portfolio helps you showcase your coding work and project progress publicly. Employers often review GitHub profiles to evaluate practical ability, problem-solving skills, and code quality.
A well-organized portfolio demonstrates consistent learning and technical competence. Learners in upGrad AI programs often upload course projects to GitHub to present their work to recruiters.
72. Are study groups helpful for online AI learners?
Study groups help learners stay motivated and solve problems collaboratively. Peer discussions clarify complex topics, encourage knowledge sharing, and provide accountability. Collaborative learning environments often improve consistency and understanding, especially in technically challenging subjects.
73. How should learners prepare for hands-on assignments in AI courses?
Learners should review theoretical concepts before attempting assignments and practice coding regularly. Understanding problem requirements, planning model design, and testing solutions step by step improves performance. Consistent preparation helps learners complete projects more efficiently and build stronger technical confidence.
74. What’s the difference in cost between beginner and advanced AI courses?
Beginner and advanced AI courses differ mainly in depth, duration, and learning outcomes.
- Beginner AI courses focus on foundational topics such as AI basics, Python programming, and introductory machine learning concepts. They are usually shorter and designed for learners who are new to AI.
- Advanced AI programs cover deeper technical areas such as deep learning, large language models, model deployment, and real-world AI system development. These programs often include extensive projects, mentorship, and industry-focused training.
Programs from upGrad offer both beginner-friendly learning paths and advanced AI programs that provide deeper technical skills and practical project experience.
75. What are common mistakes beginners make in AI courses?
Beginners often face challenges when learning AI, especially without consistent practice.
Common mistakes include:
- Skipping Python fundamentals and struggling with coding later
- Focusing only on theory without building practical projects
- Not practicing regularly, which slows skill development
- Ignoring data preprocessing, which affects model performance
- Not documenting projects or building a portfolio
Learners in upGrad AI programs are encouraged to work on projects and practice coding regularly to avoid these mistakes and build strong AI skills.
upGrad Learner Support
Talk to our experts. We are available 7 days a week, 10 AM to 7 PM
Indian Nationals
Foreign Nationals
%20(2)-db0b6f38da9c485faf76e366793c9b9e.webp&w=3840&q=75)